Immuta Proof of Value (POV)
Prerequisite: Immuta is installed.
Introduction
Welcome to your Immuta Proof of Value (POV)!
This POV guide has been built to help you get the most out of your Immuta experience in the shortest amount of time possible. It’s not to say you should limit your testing to these themes, we encourage you to augment this guide with your own specific use cases, that’s where our power really shines. But we also recommend you tackle this guide on the topics that interest you to set the foundation for your own use cases.
Vision
If the vision of why you need Immuta doesn’t align with our vision of Immuta - maybe we shouldn’t waste your time, right? So let us tell you our vision for Immuta.
Our vision: To enable the management and delivery of trusted data products at scale.
What does that mean? We allow you to apply engineering principles to how you manage data. This will give your team the agility to lower time-to-data across your organization while meeting your stringent and granular compliance requirements. Immuta allows massively scalable, evolvable (yet understandable) automation around data policies; creates stability and repeatability around how those policies are maintained, in a way that allows distributed stewardship across your organization, but provides consistency of enforcement across your data ecosystem no matter your compute/data warehouse; and fosters more availability of data through the use of highly granular data controls (it’s easier to slice a pizza with a knife than a snow shovel) with little performance overhead.
How to Use This Guide
This guide is broken into seven themes of Immuta:
- Scalability and Evolvability
- Understandability
- Stability and Repeatability
- Distributed Stewardship
- Consistency
- Availability
- Performance
Each of these are foundational concepts to applying engineering principles to data management. Each section will provide a quick overview of the theme. After reading that overview, if it is of interest to you, there are walkthroughs of specific Immuta features aligned to those themes tied to data tables we will help you populate as part of this POV. You of course are welcome to try the concepts against your own data. You can skip sections that are less important/relevant to you as well, up to you.
Each walkthrough also contains an “anti-pattern” section. Anti-patterns are design decisions that seem smart on the surface, but actually cause unforeseen issues and paint you in a corner in the long run. These anti-patterns have been experienced by our Immuta team over the years working in highly complex environments in the US Intelligence Community where anti-patterns, and the problems associated with them, could mean loss of lives. They are why we built Immuta in the first place. We find these anti-patterns across customers and open source projects and call them out specifically so you can effectively compare and contrast Immuta with other solutions and designs you may have or are evaluating.
By the end of this guide, you should have a strong understanding of the value proposition of Immuta as well as the features and functions to more quickly apply it to your real internal use cases, which we highly recommend you do as part of the POV. Note that this POV guide assumes you already have Immuta installed and running.
Themes
Scalability and Evolvability
Do you find yourself spending too much time managing roles and defining permissions in your system? When there are new requests for data, or a policy change, does this cause you to spend an inordinate amount of time to make those changes? Scalability and evolvability will completely remove this burden. When you have a scalable and evolvable data management system, it allows you to make changes that impact hundreds if not thousands of tables at once, accurately. It also allows you to evolve your policies over time with minor changes or no changes at all, through future-proof policy logic.
Lack of scalability and evolvability are rooted in the fact that you are attempting to apply a coarse role-based access control (RBAC) model to your modern data architecture. Using Apache Ranger, a well known legacy RBAC system built for Hadoop, as an example, independent research has shown the explosion of management required to do the most basic of tasks with an RBAC system: https://www.dataplatformschool.com/blog/apache-ranger-and-cloud-adoption-readiness/
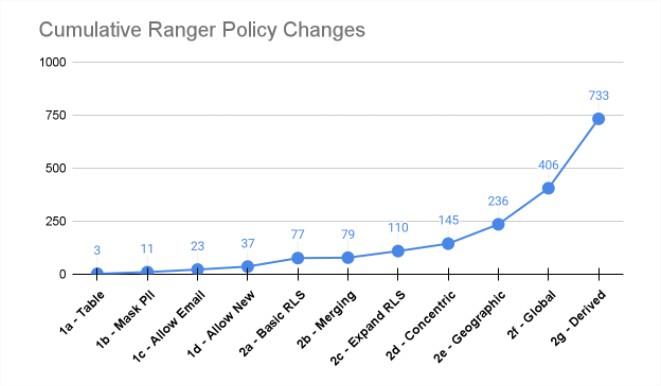
In a scalable solution such as Immuta, that count of policy changes required will remain extremely low, providing the scalability and evolvability. GigaOm researched this exactly, comparing Immuta’s ABAC model to what they called Ranger’s RBAC with Object Tagging (OT-RBAC) model and showed a 75 times increase in policy management with Ranger.
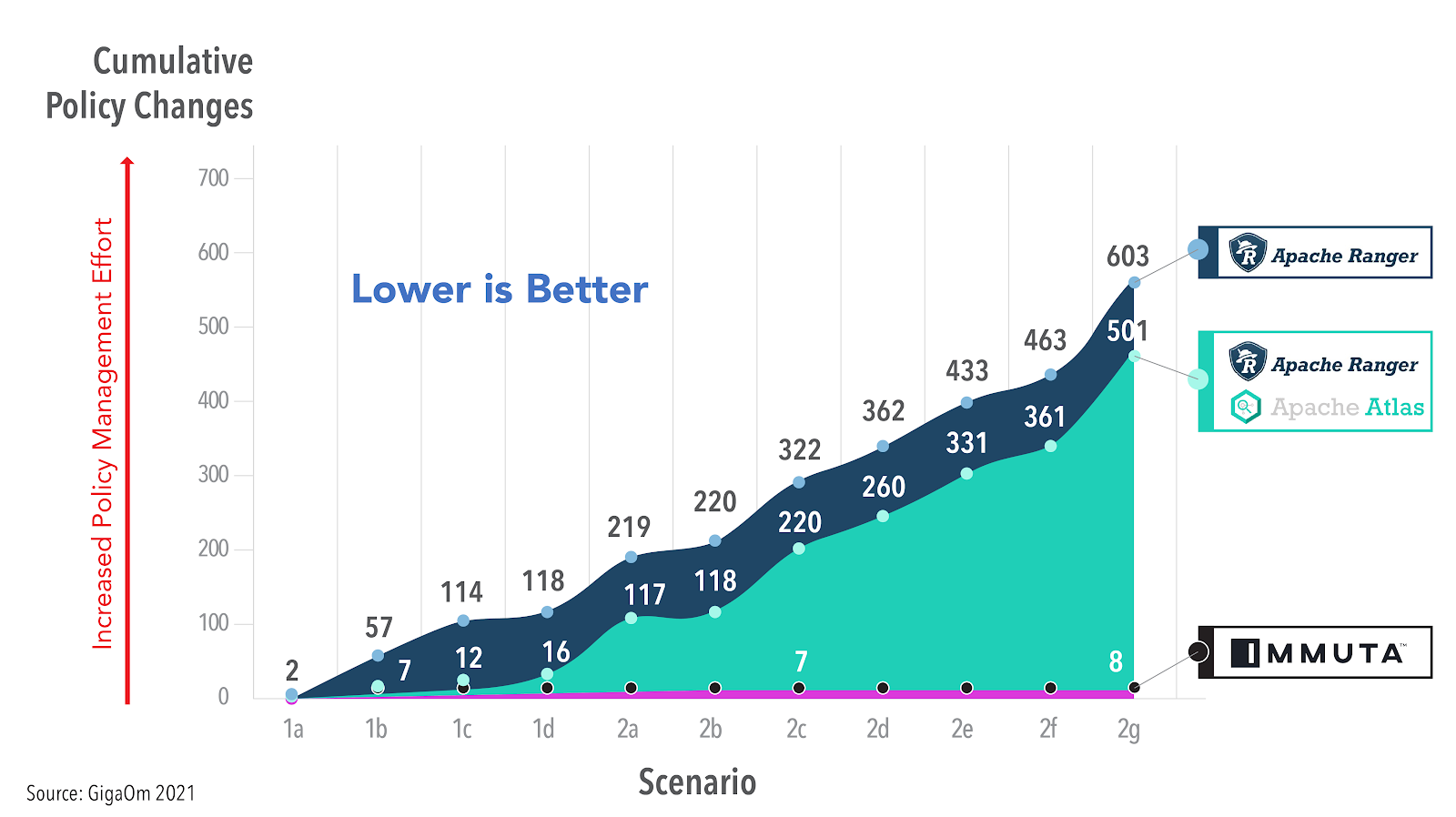
https://gigaom.com/report/cloud-data-security/
-
Value to you: You have more time to spend on the complex tasks you should be spending time on and you don’t fear making a policy change.
-
Value to the business: Policies can be easily enforced and evolved, allowing the business to be more agile and decrease time-to-data across your organization and avoid errors.
Walkthroughs
- Schema Monitoring and Automatic Sensitive Data Discovery
- Separating Policy Definition from Role Definition: Dynamic Attributes
- Policy Boolean Logic
- Exception-Based Policy Authoring
- Hierarchical Tag-Based Policy Definitions
- Subscription Policies: Benefits of Attribute-Based Table GRANTs
- Purpose-Based Exceptions
Understandability
If you can’t prove you are applying controls correctly, does it even count? In other words, how can you prove to your legal, compliance, Chief Data Officer, etc that you’ve translated regulation, typically in written form, to code-based policy logic correctly?
Obviously the prior section, scalability and evolvability help solve this problem, because they remove the amount of policies that must be defined (and reviewed). However, if you define policy buried in SQL and complex interfaces only you can understand and prove, to include history of change, you have a trust but not-verify environment that is ripe for error. In addition to scalability and evolvability removing complexity, Immuta’s platform can also present policy in a natural language form, easily understood, along with an audit history of change to create a trust and verify environment.
-
Value to you: You can easily prove policy is being implemented correctly to business leaders concerned with compliance and risk.
-
Value to the business: Ability to meet any audit obligations to external parties and/or to your customers.
Walkthroughs
Stability and Repeatability
Up until now we’ve shown you how to build scalable, evolvable, and understandable policy through the Immuta user interface. However, to get stability and repeatability, you as engineers want and need to apply software engineering principles to how you manage policy. This is the automation around Immuta just like you need automation around your infrastructure and data pipelines.
Immuta was built with the “as-code” movement in mind, allowing you to, if desired, treat Immuta as ephemeral and represent state in source control.
-
Value to you: You can merge data policy management into your existing engineering paradigms and toolchains, allowing full automation of every component of Immuta.
-
Value to the business: Reduce time-to-data across the organization because policy management is stable and your time is being spent on more complex initiatives.
Walkthrough
Distributed Stewardship
Heard of data mesh? As first defined by Zhamak Dehghani, “a data mesh is a type of data platform architecture that embraces the ubiquity of data in the enterprise by leveraging a domain-oriented, self-serve design.” You may have a data mesh and not even know it, for example, jurisdictions with strong data protections generally exert extraterritorial controls that prevent consumer or citizen data from being accessed or processed in other jurisdictions that do not afford comparable data protections and controls. What it means in practice for data management is that you need distributed stewardship for your data domains (physical and/or logical) across your organization. Put more concretely, you can’t have single “god” administrators that control everything from an access management perspective.
Immuta enables fine-grained data ownership and controls over organizational domains, allowing a data mesh environment for sharing data - embracing the ubiquity of your organization.
-
Value to you: You can enable different parts of your organization to manage their data policies in a self-serve manner without involving you in every step.
-
Value to the business: Make data available across the organization without the need to centralize both the data and authority over the data. This will free your organization to share more data more quickly than ever before.
Walkthroughs
Consistency
This section is only relevant if you are using more than one data warehouse / compute, for example, Databricks and Snowflake. Just like the big data era required the separation of compute from storage to scale, the “data compliance era” requires the separation of policy from compute to scale. This was made evident in the scalability and evolvability section, but requires a bit more critical details.
Legacy solutions, such as Apache Ranger, can only substantiate the abstraction of policy from compute in the Hadoop ecosystem. This is due to inconsistencies in how Ranger enforcement has been implemented in the other downstream compute/warehouse engines. That inconsistency arises not only from ensuring row, column, and anonymization techniques work the same in Databricks as they do in Snowflake, for example, but also from the need for additional roles to be created and managed in each system separately and inconsistently from the policy definitions. With Immuta, you have complete consistency without forcing new roles to be created into each individual warehouse’s paradigm.
With inconsistency comes complexity, both for your team and the downstream analysts trying to read data (for example, have to know what role to assume). That complexity from inconsistency removes all value of separating policy from compute. With Immuta, you are provided complete consistency.
-
Value to you: You can build policy once, in a single location, and have it enforced scalably and consistently across all your data warehouses. This is the foundational piece to all sections above.
-
Value to the business: None of the other section’s business values are possible without this foundational piece.
Walkthrough
Availability (of Data)
As an engineer, this probably is not what you think of when you hear availability, we are not talking about your data warehouse availability. In this case we mean availability of data - as much as possible.
When most think of data access control, they see it as a blocker, a brake on a car, if you will. When in fact, with fine-grained access controls and advanced anonymization techniques, it’s the opposite. For example, if the only trick up your sleeve is to grant or deny access to a table, then that’s it, you need to decide if the user can see the whole table or not. This leads to over-hiding or over-sharing. But it goes deeper, even if you can grant/deny at the column level, that still becomes a binary decision on if the user should see that column or not. Instead of a binary decision, anonymization techniques can be applied to columns to “fuzz” data just enough to provide the utility required while at the same time meet rigorous privacy and control requirements.
Availability of these highly granular decisions at the access control level is the car accelerator, not the brake: we find organizations can increase data access by over 50% in some cases when using Immuta.
-
Value to you: You are no longer caught in the middle between compliance and analysts. You can allow analysts access to more data than ever before while keeping compliance happy.
-
Value to the business: More data than ever at the fingertips of your analysts and data scientists (we’ve seen examples of up to 50% more). Your business can thrive on being data driven.
Walkthroughs
Performance
Last but not least, performance. What good is all the benefits provided by Immuta if it completely slows down all query workloads? To be clear, with increased security there is some decrease in performance. Immuta gives you the flexibility to decide how much security is appropriate for your use case given the overhead associated with that security.
Performance is tied to how Immuta implements policy enforcement. Rather than requiring a copy of data to be created, Immuta enforces policy live and this is done differently based on the warehouse/compute in question. Understanding the Immuta enforcement mechanisms will allow you to more effectively understand and evaluate Immuta performance.
-
Plugin: This enforcement is done by Immuta slightly altering the query natively in the database (with SQL). The overhead associated with this lies in checking in on the policy decision (which are cached) and any logic core to the policy that is injected into the plan. Compute/Warehouses: Databricks, Starburst (Trino).
-
Policy Push: This enforcement is done by Immuta creating a single view on top of the original table and baking all policy logic into that view. In this case, the view only changes when there is a policy change, so policy decision check overhead is eliminated and any overhead is associated with the logic of the policy in the view. Compute/Warehouses: Snowflake, Synapse, Redshift, Databricks SQL.
You can read details on our internal TPC-DS performance benchmark1 results on Databricks (plugin) here. However, we understand you probably want to test this yourself, so here are guided walkthroughs to simplify running TPC-DS performance benchmark results on Immuta-protected tables.
Walkthroughs
-
TPC-DS data has been used extensively by Database and Big Data companies for testing performance, scalability and SQL compatibility across a range of Data Warehouse queries — from fast, interactive reports to complex analytics. It reflects a multidimensional data model of a retail enterprise selling through 3 channels (stores, web, and catalogs), while the data is sliced across 17 dimensions including Customer, Store, Time, Item, etc. The bulk of the data is contained in the large fact tables: Store Sales, Catalog Sales, Web Sales — representing daily transactions spanning 5 years. ↩