Separating Policy Definition from Role Definition: Dynamic Attributes
Prerequisites: Before using this walkthrough, please ensure that you’ve first done the Parts 1-5 of the POV Data Setup and the Schema Monitoring and Automatic Sensitive Data Discovery walkthrough.
Overview
When building access control into our database platforms we are all used to a concept called Role Based Access Control (RBAC). Roles both define who is in them, but also determine what those users get access to. A good way to think about this is Roles conflate the who and what: who is in them and what they have access to (but lack the why).
In contrast, Attribute Based Access Control (ABAC) allows you to decouple your roles from what they have access to, essentially separating the what and why from the who, which also allows you to explicitly explain the “why” in the policy. This gives you an incredible amount of scalability and understandability in policy building. Note this does not mean you have to throw away your roles necessarily, you can make them more powerful and likely scale them back significantly.
If you remember this picture and article from the start of this POV, most of the Ranger, Snowflake, Databricks, etc. access control scalability issues are rooted in the fact that it’s an RBAC model vs ABAC model. Apache Ranger Evaluation for Cloud Migration and Adoption Readiness
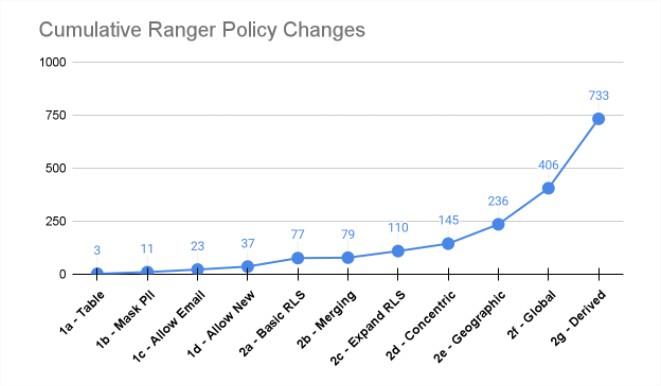
This walkthrough will run you through a very simple scenario that shows why separating the who from the what is so critical to scalability and future proofing policies.
Business Value
If you only have to manage 7 understandable policies vs 700 - wouldn’t you want to? That’s the real value here.
- Scalability: Far fewer policies and roles to manage.
- Understandability: Policies (and roles) are clearly understood. No one super user is required to explain what is going on.
- Evolvability: No fear of making changes, changes are made easily, again, without the need for super user tribal knowledge.
- Durability: Changes in data and users will not result in data leaks.
Because of this, the business reaps
- Increased revenue: accelerate data access / time to data.
- Decreased cost: operating efficiently at scale, agility at scale, data engineers aren’t spending time managing roles and complex policies.
- Decreased risk: prove policy easily, avoid policy errors, understand what policy is doing.
Building Row Level Security with an ABAC model
Assumptions: Your user has the following permissions in Immuta (note you should have these by default if you were the initial user on the Immuta installation):
- USER_ADMIN: in order to change attributes on users
- GOVERNANCE: in order to build policy against any table in Immuta OR
- “Data Owner” of the registered tables from Part 4 without the GOVERNANCE permission. (You likely are the Data Owner and have GOVERNANCE permission.)
This is a simple row-level policy that will restrict what countries you see in the “Immuta Fake Credit Card Transactions” table.
Give yourself (and other users) attributes
In order to do ABAC, we need to have attributes or groups assigned to you to drive policy. With Immuta these can come from anywhere (we mean literally anywhere), and Immuta will aggregate them to use in policy. Most commonly these come from your identity manager, such as LDAP, Active Directory, Okta, etc., but for simplicity sake, we are going to assign attributes to you in Immuta.
- Click the People icon and select Users in the left sidebar.
- Select your name and click + Add Attributes.
- In the Add Attributes menu, type Country in the Attribute field and click create.
- In the Attribute value field, type US and click create. Repeat the same process to add JP as an attribute value.
- Repeat these steps for the non-admin user you created in Part 3 of the POV Data Setup. However, leave off JP and ONLY give US to that non-admin user.
Look at the data
- Follow our Query Your Data Guide to run a query against the Immuta Fake Credit Card Transactions data in your compute/warehouse of choice to see the data before we create the policy. You can query with both your admin and non-admin user (if you were able to create a non-admin user).
- In the Immuta UI, look at the Data Dictionary for the Immuta Fake Credit Card Transactions table
(you can do this by visiting the data source in Immuta and clicking the Data Dictionary tab); notice
that the column
transaction_countryis tagged withDiscovered.Entity.Location. This will be important when policy building.
Building the policy
- Click the Policies icon in the left sidebar of the Immuta console. (Note: This is not the Policy tab in the “Immuta Fake Credit Card Transactions” data source; that tab is for local policies).
- On the Data Policies tab, click + Add Data Policy.
- Name the policy: RLS walkthrough.
- Select the action Only show rows.
- Leave the sub-action as where user.
- Set the qualification as possesses attribute.
- Set the attribute key as Country. (Remember, we added those US and JP attributes to you under Country.)
- Set the field as
Discovered.Entity.Location. (Remember, thetransaction_countrycolumn was tagged this.) - Change for everyone except to for everyone. This means there are no exceptions to the policy.
- Click Add.
- Leave the default circumstance Where should this policy be applied? with
On data sources with columns tagged
Discovered.Entity.Location. This was chosen because it was the tag you used when building the policy.
You can further refine where this policy is applied by adding another circumstance:
- Click + Add Another Circumstance.
- Change the or to an and.
- Select tagged for the circumstance. (Make sure you pick “tagged” and not “with columns tagged.”)
- Type in Immuta POV for the tag name. (Remember, this was the tag you created in Schema Monitoring and Automatic Sensitive Data Discovery.) Note that if you are a Data Owner of the tables without GOVERNANCE permission, the policy will be automatically limited to the tables you own.
- Click Create Policy and Activate Policy.
Now the policy is active and easily understandable.
We are saying that the user must have a matching Country attribute to the value in the column transaction_country
in order to see that row and there are no exceptions to that policy. However, there’s a lot of hidden value in how
you built this policy so easily:
-
Because you separated who the user is (their Country) from the policy definition (above) the user’s country is injected dynamically at runtime, this is the heart of ABAC. In an RBAC model this is not possible because the who and the what are conflated. You would have to create a Role PER COUNTRY. Not only that, you would also have to create a Role per combination of Country (remember, you had US and JP). RBAC is very similar to writing code without being able to use variables. Some vendors will claim you can fix this limitation by creating a lookup table that mimics ABAC, however, when that is done, you remove all your policy logic from your policy engine and instead place it in this lookup table.
-
We also didn’t care how the
transaction_countrycolumn was named/spelled because we based the policy on the logical tag, not the physical table(s). If you had another table with that same tag but thetransaction_countrycolumn spelled differently, the policy would have still worked. This allows you to write the policy once and have it apply to all relevant tables based on your tags, remembering Immuta can auto-discover many relevant tags. -
If you add a new user with a never before seen combination of Countries, in the RBAC model, you would have to remember to create a new policy for them to see data. In the ABAC model it will “just work” since everything is dynamic - future proofing your policies.
Look at the data again to prove the policy is working:
- Follow our Query Your Data Guide to run a query against the Immuta Fake Credit Card Transactions data in your compute/warehouse of choice to see the data after we created the policy. You can query with both your admin and non-admin user (if you were able to create a non-admin user).
- Notice that the admin user will only see US and JP, and the non-admin user only sees US.
Anti-Patterns
RBAC is an anti-pattern because you conflate the who with the what. Again, it’s like writing code without being able to use variables. If you were to write this policy with Ranger you would end up with hundreds if not thousands of policies because you need to account for every unique country combination. Doing this with groups or roles in Databricks and Snowflake would be the same situation.
You also cannot specify row-level policies based on tags (only column masking policies), so not only do you need all those Roles described above, but you also need to recreate those policies over and over again for every relevant table.
We have seen this in real customer use cases. In one great example we required 1 policy in Immuta for the equivalent controls requiring 96 rules in Ranger. There’s also of course the independent study referenced at the start of this walkthrough as well.
For more reading on the RBAC anti-pattern: Data Governance Anti-Patterns: Stop Conflating Who, Why, and What
More reading on RBAC vs ABAC in general: Role-Based Access Control vs. Attribute-Based Access Control — Explained
And if you really want to go deep, NIST on ABAC: Guide to Attribute Based Access Control (ABAC) Definition and Considerations
Next Steps
Feel free to return to the POV Guide to move on to your next topic.