Immuta Integrations
Immuta does not require users to learn a new API or language to access data exposed there. Instead, Immuta integrates with existing tools and ongoing work while remaining invisible to downstream consumers. This page outlines those integrations.
Snowflake
The Snowflake integration differs based on your Snowflake Edition:
- Snowflake Integration Using Snowflake Governance Features: With this integration, policies administered in Immuta are pushed down into Snowflake as Snowflake governance features (row access policies and masking policies). This integration requires Snowflake Enterprise Edition or higher.
- Snowflake Integration Without Snowflake Governance Features: With this integration, policies administered by Immuta are pushed down into Snowflake as views with a 1-to-1 relationship to the original table and all policy logic is contained in that view.
Click a link below for details about each question:
- How does my integration work in Immuta?
- How do I configure it?
- How do I connect my data?
- How do I protect my data?
- How do I manage data sources?
- How do I access and query data?
- How do I audit data access?
Databricks Unity Catalog
This integration allows you to manage multiple Databricks workspaces through Unity Catalog while protecting your data with Immuta policies. Instead of manually creating UDFs or granting access to each table in Databricks, you can author your policies in Immuta and have Immuta manage and enforce Unity Catalog access-control policies on your data in Databricks clusters or SQL warehouse.
- How does my integration work in Immuta?
- How do I configure it?
- How do I connect my data?
- How do I protect my data
- How do I manage data sources?
- How do I access and query data?
- How do I audit data access?
Databricks Spark integration with Unity Catalog support
Immuta’s Databricks Spark integration with Unity Catalog support uses a custom Databricks plugin to enforce Immuta policies on a Databricks cluster with Unity Catalog enabled. This integration allows you to add your tables to the Unity Catalog metastore so that you can use the metastore from any workspace while protecting your data with Immuta policies.
- How does my integration work in Immuta?
- How do I configure it?
- How do I connect my data?
- How do I protect my data
- How do I manage data sources?
- How do I access and query data?
- How do I audit data access?
Databricks Spark
This integration enforces policies on Databricks tables registered as data sources in Immuta, allowing users to query policy-enforced data on Databricks clusters (including job clusters). Immuta policies are applied to the plan that Spark builds for users' queries, all executed directly against Databricks tables.
- How does my integration work in Immuta?
- How do I configure it?
- How do I connect my data?
- How do I protect my data?
- How do I manage data sources?
- How do I access and query data?
- How do I audit data access?
Starburst (Trino)
Deprecation notice
Support for this integration has been deprecated. Use the Starburst (Trino) v2.0 integration instead.
The Starburst (Trino) integration enables Immuta to apply policies directly in Starburst and Trino clusters without going through a proxy. This means users can use their existing Starburst and Trino tooling (querying, reporting, etc.) and have per-user policies dynamically applied at query time.
- How does my integration work in Immuta?
- How do I configure it?
- How do I connect my data?
- How do I protect my data?
- How do I manage data sources?
- How do I access and query data?
- How do I audit data access?
Starburst (Trino) Integration v2.0
The Starburst (Trino) integration v2.0 allows you to access policy-protected data directly in your Starburst (Trino) catalogs without rewriting queries or changing your workflows. Instead of generating policy-enforced views and adding them to an Immuta catalog that users have to query (like in the legacy Starburst (Trino) integration), Immuta policies are translated into Starburst (Trino) rules and permissions and applied directly to tables within users’ existing catalogs.
- How does my integration work in Immuta?
- How do I configure it?
- How do I connect my data?
- How do I protect my data?
- How do I manage data sources?
- How do I access and query data?
- How do I audit data access?
Redshift
With the Redshift integration, Immuta applies policies directly in Redshift. This allows data analysts to query their data directly in Redshift instead of going through a proxy.
- How does my integration work in Immuta?
- How do I configure it?
- How do I connect my data?
- How do I protect my data?
- How do I manage data sources?
- How do I access and query data?
- How do I audit data access?
Azure Synapse Analytics
The Azure Synapse Analytics integration allows Immuta to apply policies directly in Azure Synapse Analytics dedicated SQL pools without needing users to go through a proxy. Instead, users can work within their existing Synapse Studio and have per-user policies dynamically applied at query time.
- How does my integration work in Immuta?
- How do I configure it?
- How do I connect my data?
- How do I protect my data?
- How do I manage data sources?
- How do I access and query data?
- How do I audit data access?
Amazon S3
Private preview
This integration is available to select accounts. Reach out to your Immuta representative for details.
The Amazon S3 integration allows users to apply subscription policies to data in S3 to restrict what prefixes, buckets, or objects users can access. To enforce access controls on this data, Immuta creates S3 grants that are administered by S3 Access Grants, an AWS feature that defines access permissions to data in S3.
- How does my integration work in Immuta?
- How do I configure it?
- How do I connect my data?
- How do I protect my data?
- How do I manage data sources?
- How do I access and query data?
Google BigQuery
Private preview
This integration is available to select accounts. Reach out to your Immuta representative for details.
In this integration, Immuta generates policy-enforced views in your configured Google BigQuery dataset for tables registered as Immuta data sources.
- How does my integration work in Immuta?
- How do I configure it?
- How do I connect my data?
- How do I protect my data?
- How do I manage data sources?
- How do I access and query data?
External Catalogs
Users who want to use tagging capabilities outside of Immuta and pull tags from external table schemas can connect Collibra or Alation as an external catalog. Once they have been connected, Immuta will ingest a data dictionary from the catalog that will apply data source and column tags directly onto queryable data sources. These tags can then be used to write and drive policies.
If users have another catalog, or have customized their Collibra or Alation integrations, they can connection through the REST Catalog using the Immuta API.
Users can also connect a Snowflake account to allow Immuta to ingest Snowflake tags onto Snowflake data sources.
- How does my catalog work with Immuta?
- How do I configure it?
- How do I automatically discover and tag sensitive data?
External IAMs
External identity managers configured in Immuta allow users to authenticate using an existing identity management system and can optionally be used to synchronize user groups and attributes into Immuta.
Feature, Audit, and Policy Support
Feature Support
The table below outlines the features supported by each of Immuta's integrations.
| Project Workspaces | Tag Ingestion | User Impersonation | Native Query Audit | Multiple Integrations | |
|---|---|---|---|---|---|
| Snowflake |  |
|
|
|
|
| Databricks Unity Catalog |  |
|
|
|
|
| Databricks Spark | |
|
|
|
|
| Databricks SQL | |
|
|
|
|
| Starburst (Trino) | |
|
|
|
|
| Redshift | |
|
|
|
|
| Azure Synapse Analytics | |
|
|
|
|
Audit Support Matrix
The table below outlines the audit support by each of Immuta's integrations and what information is included in the audit logs.
| Snowflake | Databricks Spark | Databricks Unity Catalog | Starburst (Trino) | Redshift | Azure Synapse Analytics | |
|---|---|---|---|---|---|---|
| Native query audit type | Legacy audit and UAM | Legacy audit and UAM | Legacy audit and UAM | Legacy audit | |
|
| Table and user coverage | Registered data sources and users | Registered data sources and users | All tables and users | Registered data sources and users | |
|
| Object queried | |
|
1 | |
|
|
| Columns returned | |
|
|
2 | |
|
| Query text | |
|
3 | |
|
|
| Unauthorized information | 4 | |
5 | |
|
|
| Policy details | |
|
|
6 | |
|
| User's entitlements | |
|
|
7 | |
|
Legend:
- This is available and the information is included in audit logs.
- This is not available and the information is not included in audit logs.
- There is limited availability; see the footnote for more details.
Policy Support Matrix
Certain policies are unsupported or supported with caveats, depending on the integration:
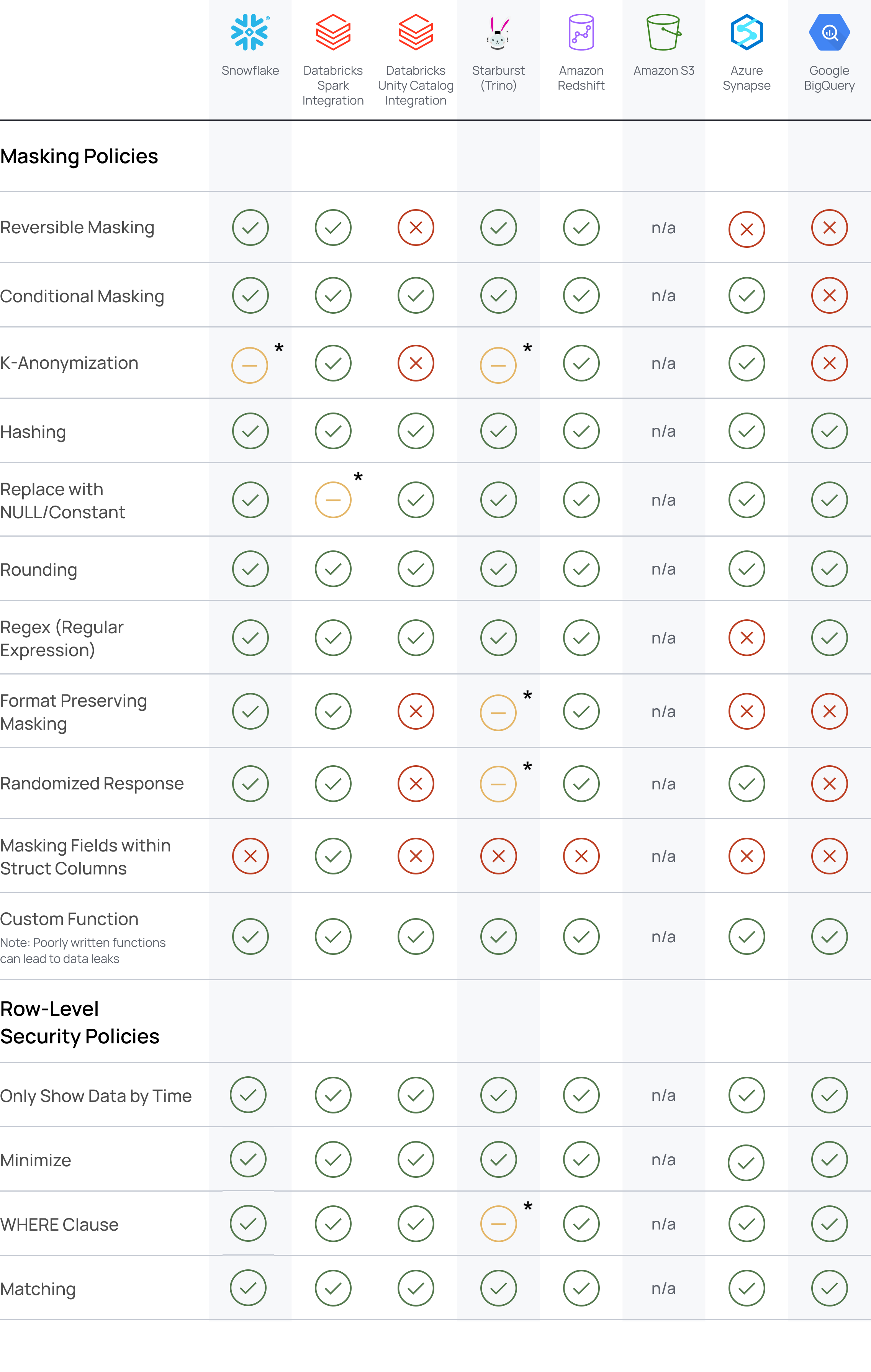
*Supported with Caveats:
- On Databricks data sources, joins will not be allowed on data protected with replace with NULL/constant policies.
- On Trino data sources, the Immuta functions
@iamand@interpolatedComparisonfor WHERE clause policies can block the creation of views.
For details about each of these policies, see the Policies in Immuta page.
-
For some queries, Databricks Unity Catalog does not report the target data source for the data access operation. In these cases the activity is audited, yet the audit record in Immuta will not include the target data source information. ↩
-
Audit will only return the columns that have been masked by an Immuta policy. ↩
-
Audit will return the
commandTextwhich often shows the query made. ↩ -
Unauthorized information is only available when the integration has table replacements enabled. ↩
-
Unauthorized queries will be audited when available. ↩
-
Audit will show policy details through the
maskedColumnsvalue. ↩ -
Only the user's projects will be audited. ↩