Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Additional overhead: In relation to the Python & SQL cluster policy, this configuration trades some additional overhead for added support of the R language.
In this configuration, you are able to rely on the Databricks-native security controls. The key security control here is the enablement of process isolation. This prevents users from obtaining unintentional access to the queries of other users. In other words, masked and filtered data is consistently made accessible to users in accordance with their assigned attributes.
Like the Python & SQL configuration, Py4j security is enabled for the Python & SQL & R configuration. However, because R has been added Immuta enables the SecurityManager, in addition to Py4j security, to provide more security guarantees. For example, by default all actions in R execute as the root user; among other things, this permits access to the entire filesystem (including sensitive configuration data), and, without iptable restrictions, a user may freely access the cluster’s cloud storage credentials. To address these security issues, Immuta’s initialization script wraps the R and Rscript binaries to launch each command as a temporary, non-privileged user with limited filesystem and network access and installs the Immuta SecurityManager, which prevents users from bypassing policies and protects against the above vulnerabilities from within the JVM.
Consequently, the cost of introducing R is that the SecurityManager incurs a small increase in performance overhead; however, average latency will vary depending on whether the cluster is homogeneous or heterogeneous. (In homogeneous clusters, all users are at the same level of groups/authorizations; this is enforced externally, rather than directly by Immuta.)
Many Python ML classes (such as LogisticRegression, StringIndexer, and DecisionTreeClassifier) and dbutils.fs are unfortunately not supported with Py4J security enabled. Users will also be unable to use the Databricks Connect client library.
When users install third-party Java/Scala libraries, they will be denied access to sensitive resources by default. However, cluster administrators can specify which of the installed Databricks libraries should be trusted by Immuta.
For full details on Databricks’ best practices in configuring clusters, read their governance documentation.
Py4j security disabled: In addition to support for Python, SQL, and R, this configuration adds support for additional Python libraries and utilities by disabling Databricks-native Py4j security.
This configuration does not rely on Databricks-native Py4j security to secure the cluster, while process isolation is still enabled to secure filesystem and network access from within Python processes. On an Immuta-enabled cluster, once Py4J security is disabled the Immuta SecurityManager is installed to prevent nefarious actions from Python in the JVM. Disabling Py4J security also allows for expanded Python library support, including many Python ML classes (such as LogisticRegression, StringIndexer, and DecisionTreeClassifier) and dbutils.fs.
By default, all actions in R will execute as the root user. Among other things, this permits access to the entire filesystem (including sensitive configuration data). And without iptable restrictions, a user may freely access the cluster’s cloud storage credentials. To properly support the use of the R language, Immuta’s initialization script wraps the R and Rscript binaries to launch each command as a temporary, non-privileged user. This user has limited filesystem and network access. The Immuta SecurityManager is also installed to prevent users from bypassing policies and protects against the above vulnerabilities from within the JVM.
The SecurityManager will incur a small increase in performance overhead; average latency will vary depending on whether the cluster is homogeneous or heterogeneous. (In homogeneous clusters, all users are at the same level of groups/authorizations; this is enforced externally, rather than directly by Immuta.)
When users install third-party Java/Scala libraries, they will be denied access to sensitive resources by default. However, cluster administrators can specify which of the installed Databricks libraries should be trusted by Immuta.
A homogeneous cluster is recommended for configurations where Py4J security is disabled. If all users have the same level of authorization, there would not be any data leakage, even if a nefarious action was taken.
For full details on Databricks’ best practices in configuring clusters, read their governance documentation.
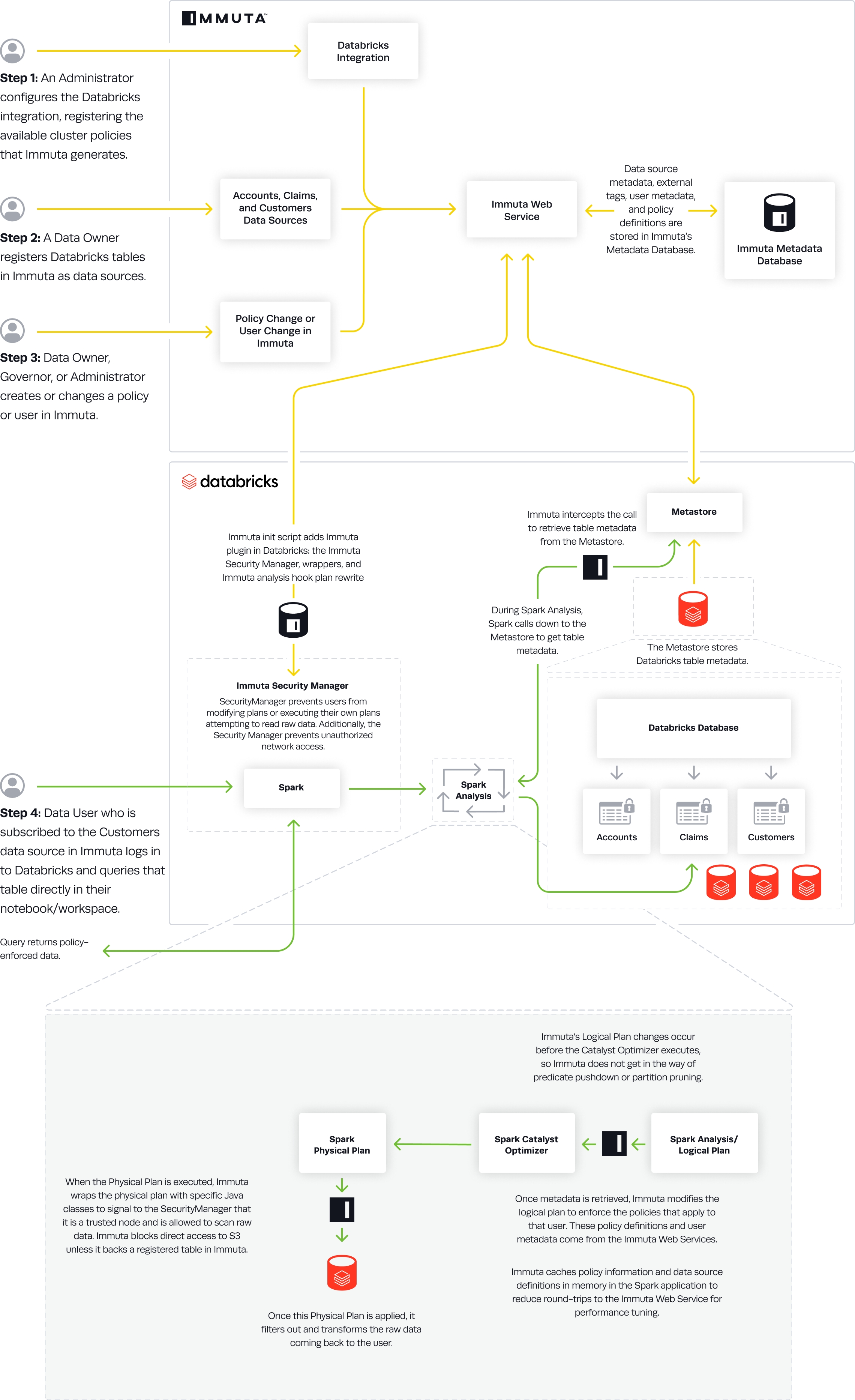
This page provides an overview of the Databricks Spark integration. For installation instructions, see the Databricks Installation Introduction.
Databricks Spark is a plugin integration with Immuta. This integration allows you to protect access to tables and manage row-, column-, and cell-level controls without enabling table ACLs or credential passthrough. Policies are applied to the plan that Spark builds for a user's query and enforced live on-cluster.
An Application Admin will configure Databricks Spark with either the
Simplified Databricks Spark Configuration on the Immuta App Settings page
Manual Databricks Spark Configuration where Immuta artifacts must be downloaded and staged to your Databricks clusters
In both configuration options, the Immuta init script adds the Immuta plugin in Databricks: the Immuta Security Manager, wrappers, and Immuta analysis hook plan rewrite. Once an administrator gives users Can Attach To entitlements on the cluster, they can query Immuta-registered data source directly in their Databricks notebooks.
Simplified Databricks Spark configuration additional entitlements
The credentials used to do the Simplified Databricks Spark configuration with automatic cluster policy push must have the Allow cluster creation entitlement.
This will give Immuta temporary permission to push the cluster policies to the configured Databricks workspace and overwrite any cluster policy templates previously applied to the workspace.
Best practice
Test the integration on an Immuta-enabled cluster with a user that is not a Databricks administrator.
You should register entire databases with Immuta and run Schema Monitoring jobs through the Python script provided during data source registration. Additionally, you should use a Databricks administrator account to register data sources with Immuta using the UI or API; however, you should not test Immuta policies using a Databricks administrator account, as they are able to bypass controls.
A Databricks administrator can control who has access to specific tables in Databricks through Immuta Subscription Policies or by manually adding users to the data source. Data users will only see the immuta database with no tables until they are granted access to those tables as Immuta data sources.
immuta DatabaseWhen a table is registered in Immuta as a data source, users can see that table in the native Databricks database and in the immuta database. This allows for an option to use a single database (immuta) for all tables.
After data users have subscribed to data sources, administrators can apply fine-grained access controls, such as restricting rows or masking columns with advanced anonymization techniques, to manage what the users can see in each table. More details on the types of data policies can be found on the Data Policies page, including an overview of masking struct and array columns in Databricks.
Note: Immuta recommends building Global Policies rather than Local Policies, as they allow organizations to easily manage policies as a whole and capture system state in a more deterministic manner.
All access controls must go through SQL.
Note: With R, you must load the SparkR library in a cell before accessing the data.
Usernames in Immuta must match usernames in Databricks. It is best practice is to use the same identity manager for Immuta that you use for Databricks (Immuta supports these identity manager protocols and providers. however, for Immuta SaaS users, it’s easiest to just ensure usernames match between systems.
An Immuta Application Administrator configures the Databricks Spark integration and registers available cluster policies Immuta generates.
The Immuta init script adds the immuta plugin in Databricks: the Immuta SecurityManager, wrappers, and Immuta analysis hook plan rewrite.
A Data Owner registers Databricks tables in Immuta as data sources. A Data Owner, Data Governor, or Administrator creates or changes a policy or user in Immuta.
Data source metadata, tags, user metadata, and policy definitions are stored in Immuta's Metadata Database.
A Databricks user who is subscribed to the data source in Immuta queries the corresponding table directly in their notebook or workspace.
During Spark Analysis, Spark calls down to the Metastore to get table metadata.
Immuta intercepts the call to retrieve table metadata from the Metastore.
Immuta modifies the Logical Plan to enforce policies that apply to that user.
Immuta wraps the Physical Plan with specific Java classes to signal to the SecurityManager that it is a trusted node and is allowed to scan raw data.
The Physical Plan is applied and filters out and transforms raw data coming back to the user.
The user sees policy-enforced data.
This page describes the Databricks Spark integration, configuration options, and features. See the for a tutorial on enabling Databricks and these features through the App Settings page.
The table below outlines the integrations supported for various Databricks cluster configurations. For example, the only integration available to enforce policies on a cluster configured to run on Databricks Runtime 9.1 is the Databricks Spark integration.
Legend:
The feature or integration is enabled.
The feature or integration is disabled.
Databricks instance has network level access to Immuta tenant
Permissions and access to download (outside Internet access) or transfer files to the host machine
Recommended Databricks Workspace Configurations:
Immuta supports the Custom access mode.
Supported Languages:
Python
SQL
R (requires advanced configuration; work with your Immuta support professional to use R)
Scala (requires advanced configuration; work with your Immuta support professional to use Scala)
The Immuta Databricks Spark integration supports the following Databricks features:
Audit limitations
Capturing the code or query that triggers the Spark plan makes audit records more useful in assessing what users are doing.
A user can configure multiple integrations of Databricks to a single Immuta tenant and use them dynamically or with workspaces.
Immuta does not support Databricks clusters with Photon acceleration enabled.
Scala clusters: This configuration is for Scala-only clusters.
Where Scala language support is needed, this configuration can be used in the Custom .
According to Databricks’ cluster type support documentation, Scala clusters are intended for . However, nothing inherently prevents a Scala cluster from being configured for multiple users. Even with the Immuta SecurityManager enabled, there are limitations to user isolation within a Scala job.
For a secure configuration, it is recommended that clusters intended for Scala workloads are limited to Scala jobs only and are made homogeneous through the use of or externally via convention/cluster ACLs. (In homogeneous clusters, all users are at the same level of groups/authorizations; this is enforced externally, rather than directly by Immuta.)
For full details on Databricks’ best practices in configuring clusters, read their .
This page outlines configuration details for Immuta-enabled Databricks clusters. Databricks Administrators should place the desired configuration in the Spark environment variables (recommended) or immuta_conf.xml (not recommended).
This page contains references to the term whitelist, which Immuta no longer uses. When the term is removed from the software, it will be removed from this page.
Environment variable overrides
Properties in the config file can be overridden during installation using environment variables. The variable names are the config names in all upper case with _ instead of .. For example, to set the value of immuta.base.url via an environment variable, you would set the following in the Environment Variables section of cluster configuration: IMMUTA_BASE_URL=https://immuta.mycompany.com
immuta.ephemeral.host.override
Default: true
Description: Set this to false if ephemeral overrides should not be enabled for Spark. When true, this will automatically override ephemeral data source httpPaths with the httpPath of the Databricks cluster running the user's Spark application.
immuta.ephemeral.host.override.httpPath
Description: This configuration item can be used if automatic detection of the Databricks httpPath should be disabled in favor of a static path to use for ephemeral overrides.
immuta.ephemeral.table.path.check.enabled
Default: true
Description: When querying Immuta data sources in Spark, the metadata from the Metastore is compared to the metadata for the target source in Immuta to validate that the source being queried exists and is queryable on the current cluster. This check typically validates that the target (database, table) pair exists in the Metastore and that the table’s underlying location matches what is in Immuta. This configuration can be used to disable location checking if that location is dynamic or changes over time. Note: This may lead to undefined behavior if the same table names exist in multiple workspaces but do not correspond to the same underlying data.
immuta.spark.acl.enabled
Default: true
Description: Immuta Access Control List (ACL). Controls whether Databricks users are blocked from accessing non-Immuta tables. Ignored if Databricks Table ACLs are enabled (i.e., spark.databricks.acl.dfAclsEnabled=true).
immuta.spark.acl.whitelist
Description: Comma-separated list of Databricks usernames who may access raw tables when the Immuta ACL is in use.
immuta.spark.acl.privileged.timeout.seconds
Default: 3600
Description: The number of seconds to cache privileged user status for the Immuta ACL. A privileged Databricks user is an admin or is whitelisted in immuta.spark.acl.whitelist.
immuta.spark.acl.assume.not.privileged
Default: false
Description: Session property that overrides privileged user status when the Immuta ACL is in use. This should only be used in R scripts associated with spark-submit jobs.
immuta.spark.audit.all.queries
Default: false
Description: Enables auditing all queries run on a Databricks cluster, regardless of whether users touch Immuta-protected data or not.
immuta.spark.databricks.allow.non.immuta.reads
Default: false
Description: Allows non-privileged users to SELECT from tables that are not protected by Immuta. See for details about this feature.
immuta.spark.databricks.allow.non.immuta.writes
Default: false
Description: Allows non-privileged users to run DDL commands and data-modifying commands against tables or spaces that are not protected by Immuta. See for details about this feature.
immuta.spark.databricks.allowed.impersonation.users
Description: This configuration is a comma-separated list of Databricks users who are allowed to impersonate Immuta users.
immuta.spark.databricks.dbfs.mount.enabled
Default: false
Description: Exposes the DBFS FUSE mount located at /dbfs. Granular permissions are not possible, so all users will have read/write access to all objects therein. Note: Raw, unfiltered source data should never be stored in DBFS.
immuta.spark.databricks.disabled.udfs
Description: Block one or more Immuta from being used on an Immuta cluster. This should be a Java regular expression that matches the set of UDFs to block by name (excluding the immuta database). For example to block all project UDFs, you may configure this to be ^.*_projects?$. For a list of functions, see the .
immuta.spark.databricks.filesystem.blacklist
Default: hdfs
Description: A list of filesystem protocols that this instance of Immuta will not support for workspaces. This is useful in cases where a filesystem is available to a cluster but should not be used on that cluster.
immuta.spark.databricks.jar.uri
Default: file:///databricks/jars/immuta-spark-hive.jar
Description: The location of immuta-spark-hive.jar on the filesystem for Databricks. This should not need to change unless a custom initialization script that places immuta-spark-hive in a non-standard location is necessary.
immuta.spark.databricks.local.scratch.dir.enabled
Default: true
Description: Creates a world-readable/writable scratch directory on local disk to facilitate the use of dbutils and 3rd party libraries that may write to local disk. Its location is non-configurable and is stored in the environment variable IMMUTA_LOCAL_SCRATCH_DIR. Note: Sensitive data should not be stored at this location.
immuta.spark.databricks.log.level
Default Value: INFO
Description: The SLF4J log level to apply to Immuta's Spark plugins.
immuta.spark.databricks.log.stdout.enabled
Default: false
Description: If true, writes logging output to stdout/the console as well as the log4j-active.txt file (default in Databricks).
immuta.spark.databricks.py4j.strict.enabled
Default: true
Description: Disable to allow the use of the dbutils API in Python. Note: This setting should only be disabled for customers who employ a homogeneous integration (i.e., all users have the same level of data access).
immuta.spark.databricks.scratch.database
Description: This configuration is a comma-separated list of additional databases that will appear as scratch databases when running a SHOW DATABASE query. This configuration increases performance by circumventing the Metastore to get the metadata for all the databases to determine what to display for a SHOW DATABASE query; it won't affect access to the scratch databases. Instead, use immuta.spark.databricks.scratch.paths to control read and write access to the underlying database paths.
Additionally, this configuration will only display the scratch databases that are configured and will not validate that the configured databases exist in the Metastore. Therefore, it is up to the Databricks administrator to properly set this value and keep it current.
immuta.spark.databricks.scratch.paths
Description: Comma-separated list of remote paths that Databricks users are allowed to directly read/write. These paths amount to unprotected "scratch spaces." You can create a scratch database by configuring its specified location (or configure dbfs:/user/hive/warehouse/<db_name>.db for the default location).
To create a scratch path to a location or a database stored at that location, configure
To create a scratch path to a database created using the default location,
immuta.spark.databricks.scratch.paths.create.db.enabled
Default: false
Description: Enables non-privileged users to create or drop scratch databases.
immuta.spark.databricks.single.impersonation.user
Default: false
Description: When true, this configuration prevents users from changing their impersonation user once it has been set for a given Spark session. This configuration should be set when the BI tool or other service allows users to submit arbitrary SQL or issue SET commands.
immuta.spark.databricks.submit.tag.job
Default: true
Description: Denotes whether the Spark job will be run that "tags" a Databricks cluster as being associated with Immuta.
immuta.spark.databricks.trusted.lib.uris
Description:
immuta.spark.non.immuta.table.cache.seconds
Default: 3600
Description: The number of seconds Immuta caches whether a table has been exposed as a source in Immuta. This setting only applies when immuta.spark.databricks.allow.non.immuta.writes or immuta.spark.databricks.allow.non.immuta.reads is enabled.
immuta.spark.require.equalization
Default: false
Description: Requires that users act through a single, equalized project. A cluster should be equalized if users need to run Scala jobs on it, and it should be limited to Scala jobs only via spark.databricks.repl.allowedLanguages.
immuta.spark.resolve.raw.tables.enabled
Default: true
Description: Enables use of the underlying database and table name in queries against a table-backed Immuta data source. Administrators or whitelisted users can set immuta.spark.session.resolve.raw.tables.enabled to false to bypass resolving raw databases or tables as Immuta data sources. This is useful if an admin wants to read raw data but is also an Immuta user. By default, data policies will be applied to a table even for an administrative user if that admin is also an Immuta user.
immuta.spark.session.resolve.raw.tables.enabled
Default: true
Description: Same as above, but a session property that allows users to toggle this functionality. If users run set immuta.spark.session.resolve.raw.tables.enabled=false, they will see raw data only (not Immuta data policy-enforced data). Note: This property is not set in immuta_conf.xml.
immuta.spark.show.immuta.database
Default: true
Description: This shows the immuta database in the configured Databricks cluster. When set to false Immuta will no longer show this database when a SHOW DATABASES query is performed. However, queries can still be performed against tables in the immuta database using the Immuta-qualified table name (e.g., immuta.my_schema_my_table) regardless of whether or not this feature is enabled.
immuta.spark.version.validate.enabled
Default: true
Description: Immuta checks the versions of its artifacts to verify that they are compatible with each other. When set to true, if versions are incompatible, that information will be logged to the Databricks driver logs and the cluster will not be usable. If a configuration file or the jar artifacts have been patched with a new version (and the artifacts are known to be compatible), this check can be set to false so that the versions don't get logged as incompatible and make the cluster unusable.
immuta.user.context.class
Default: com.immuta.spark.OSUserContext
Description: The class name of the UserContext that will be used to determine the current user in immuta-spark-hive. The default implementation gets the OS user running the JVM for the Spark application.
immuta.user.mapping.iamid
Default: bim
Description: Denotes which IAM in Immuta should be used when mapping the current Spark user's username to a userid in Immuta. This defaults to Immuta's internal IAM (bim) but should be updated to reflect an actual production IAM.
Ephemeral overrides best practices
Disable ephemeral overrides for clusters when using multiple workspaces and dedicate a single cluster to serve queries from Immuta in a single workspace.
If you use multiple E2 workspaces without disabling ephemeral overrides, avoid applying the where user row-level policy to data sources.
In Immuta, a Databricks data source is considered ephemeral, meaning that the compute resources associated with that data source will not always be available.
Ephemeral data sources allow the use of ephemeral overrides, user-specific connection parameter overrides that are applied to Immuta metadata operations.
When a user runs a Spark job in Databricks, Immuta plugins automatically submit ephemeral overrides for that user to Immuta for all applicable data sources to use the current cluster as compute for all subsequent metadata operations for that user against the applicable data sources.
A user runs a query on cluster B.
The Immuta plugins on the cluster check if there is a source in the Metastore with a matching database, table name, and location for its underlying data. Note: If tables are dynamic or change over time, users can disable the comparison of the location of the underlying data by setting immuta.ephemeral.table.path.check.enabled to false; disabling allows users to avoid keeping the relevant data sources in Immuta up-to-date (which would require API calls and automation).
The Immuta plugins on the cluster detect that the user is subscribed to data sources 1, 2, and 3 and that data sources 1 and 3 are both present in the Metastore for cluster B, so the plugins submit ephemeral override requests for data sources 1 and 3 to override their connections with the HTTP path from cluster B.
Since data source 2 is not present in the Metastore, it is marked as a JDBC source.
If the user attempts to query data source 2 and they have not enabled JDBC sources, they will be presented with an error message telling them to do so:
com.immuta.spark.exceptions.ImmutaConfigurationException: This query plan will cause data to be pulled over JDBC. This spark context is not configured to allow this. To enable JDBC setimmuta.enable.jdbc=truein the spark context hadoop configuration.
Ephemeral overrides are enabled by default because Immuta must be aware of a cluster that is running to serve metadata queries. The operations that use the ephemeral overrides include
Visibility checks on the data source for a particular user. These checks assess how to apply row-level policies for specific users.
Stats collection triggered by a specific user.
Validating a custom WHERE clause policy against a data source. When owners or governors create custom WHERE clause policies, Immuta uses compute resources to validate the SQL in the policy. In this case, the ephemeral overrides for the user writing the policy are used to contact a cluster for SQL validation.
High Cardinality Column detection. Certain advanced policy types (e.g., minimization and randomized response) in Immuta require a High Cardinality Column, and that column is computed on data source creation. It can be recomputed on demand and, if so, will use the ephemeral overrides for the user requesting computation.
However, ephemeral overrides can be problematic in environments that have a dedicated cluster to handle maintenance activities, since ephemeral overrides can cause these operations to execute on a different cluster than the dedicated one.
To reduce the risk that a user has overrides set to a cluster (or multiple clusters) that aren't currently up,
direct all clusters' HTTP paths for overrides to a cluster dedicated for metadata queries or
disable overrides completely.
To disable ephemeral overrides, set immuta.ephemeral.host.override in spark-defaults.conf to false.
Single-user clusters recommended
Like Databricks, Immuta recommends single-user clusters for sparklyr when user isolation is required. A single-user cluster can either be a job cluster or a cluster with credential passthrough enabled. Note: spark-submit jobs are not currently supported.
Two cluster types can be configured with sparklyr: Single-User Clusters (recommended) and Multi-User Clusters (discouraged).
: Credential Passthrough (required on Databricks) allows a single-user cluster to be created. This setting automatically configures the cluster to assume the role of the attached user when reading from storage. Because Immuta requires that raw data is readable by the cluster, the instance profile associated with the cluster should be used rather than a role assigned to the attached user.
: Because Immuta cannot guarantee user isolation in a multi-user sparklyr cluster, it is not recommended to deploy a multi-user cluster. To force all users to act under the same set of attributes, groups, and purposes with respect to their data access and eliminate the risk of a data leak, all sparklyr multi-user clusters must be equalized either by convention (all users able to attach to the cluster have the same level of data access in Immuta) or by configuration (detailed below).
In addition to the configuration for an Immuta cluster with R, add this environment variable to the Environment Variables section of the cluster:
This configuration makes changes to the iptables rules on the cluster to allow the sparklyr client to connect to the required ports on the JVM used by the sparklyr backend service.
Install and load libraries into a notebook. Databricks includes the stable version of sparklyr, so library(sparklyr) in an R notebook is sufficient, but you may opt to install the latest version of sparklyr from CRAN. Additionally, loading library(DBI) will allow you to execute SQL queries.
Set up a sparklyr connection:
Pass the connection object to execute queries:
Add the following items to the Spark Config section of the cluster:
The trustedFileSystems setting is required to allow Immuta’s wrapper FileSystem (used in conjunction with the ImmutaSecurityManager for data security purposes) to be used with credential passthrough. Additionally, the InstanceProfileCredentialsProvider must be configured to continue using the cluster’s instance profile for data access, rather than a role associated with the attached user.
Avoid deploying multi-user clusters with sparklyr configuration
It is possible, but not recommended, to deploy a multi-user cluster sparklyr configuration. Immuta cannot guarantee user isolation in a multi-user sparklyr configuration.
The configurations in this section enable sparklyr, require project equalization, map sparklyr sessions to the correct Immuta user, and prevent users from accessing Immuta native workspaces.
Add the following environment variables to the Environment Variables section of your cluster configuration:
Add the following items to the Spark Config section:
Immuta’s integration with sparklyr does not currently support
spark-submit jobs,
UDFs, or
Databricks Runtimes 5, 6, or 7.
Performance: This is the most performant policy configuration.
In this configuration, Immuta is able to rely on Databricks-native security controls, reducing overhead. The key security control here is the enablement of process isolation. This prevents users from obtaining unintentional access to the queries of other users. In other words, masked and filtered data is consistently made accessible to users in accordance with their assigned attributes. This Immuta cluster configuration relies on Py4J security being enabled.
Many Python ML classes (such as LogisticRegression, StringIndexer, and DecisionTreeClassifier) and dbutils.fs are unfortunately not supported with Py4J security enabled. Users will also be to use the Databricks Connect client library. Additionally, only Python and SQL are available as supported languages.
For full details on Databricks’ best practices in configuring clusters, read their .
Error Message: py4j.security.Py4JSecurityException: Constructor <> is not whitelisted
Explanation: This error indicates you are being blocked by Py4j security rather than the Immuta Security Manager. is strict and generally ends up blocking many ML libraries.
Solution: Turn off Py4j security on the offending cluster by setting IMMUTA_SPARK_DATABRICKS_PY4J_STRICT_ENABLED=false in the environment variables section. Additionally, because there are limitations to the security mechanisms Immuta employs on-cluster when Py4j security is disabled, ensure that all users on the cluster have the same level of access to data, as users could theoretically see (policy-enforced) data that other users have queried.
Databricks instance: Premium tier workspace and
Access to
Note: Azure Databricks authenticates users with Microsoft Entra ID. Be sure to configure your Immuta tenant with an IAM that uses the same user ID as does Microsoft Entra ID. Immuta's Spark security plugin will look to match this user ID between the two systems. See this for details.
See for a list of Databricks Runtimes Immuta supports.
: Databricks users can see the on queried tables if they are allowed to read raw data and meet specific qualifications.
: Users can register their Databricks Libraries with Immuta as trusted libraries, allowing Databricks cluster administrators to avoid Immuta security manager errors when using third-party libraries.
: Immuta supports the use of external metastores in local or remote mode.
: In addition to supporting direct file reads through workspace and scratch paths, Immuta allows direct file reads in Spark for file paths.
Users can have additional write access in their integration using project workspaces. Users can integrate a single or multiple workspaces with a single Immuta tenant. For more details, see the page.
The Immuta Databricks Spark integration cannot ingest tags from Databricks, but you can connect any of these to work with your integration.
Native impersonation allows users to natively query data as another Immuta user. To enable native user impersonation, see the page.
Immuta will audit queries that come from interactive notebooks, notebook jobs, and JDBC connections, but will not audit . Furthermore, Immuta only audits Spark jobs that are associated with Immuta tables. Consequently, Immuta will not audit a query in a notebook cell that does not trigger a Spark job, unless immuta.spark.audit.all.queries is set to true; for more details about this configuration and auditing all queries in Databricks, see .
To audit the code or query that triggers the Spark plan, Immuta hooks into Databricks where notebook cells and JDBC queries execute and saves the cell or query text. Then, Immuta pulls this information into the audits of the resulting Spark jobs. Examples of a saved cell/query and the resulting audit record are provided on the page.
In most cases, Immuta’s runs automatically from the Immuta web service. For Databricks, that automatic job is disabled because of the . In this case, Immuta requires users to download a schema detection job template (a Python script) and import that into their Databricks workspace. See the guide for details.
It is most secure to leverage an equalized project when working in a Scala cluster; however, it is not required to limit Scala to equalized projects. This document outlines security recommendations for Scala clusters and discusses the security risks involved when equalized projects are not used.
Language support: R and Scala are both supported, but require advanced configuration; work with your Immuta support professional to use these languages.
There are limitations to isolation among users in Scala jobs on a Databricks cluster, even when using Immuta’s SecurityManager. When data is broadcast, cached (spilled to disk), or otherwise saved to SPARK_LOCAL_DIR, it's impossible to distinguish between which user’s data is composed in each file/block. If you are concerned about this vulnerability, Immuta suggests that Scala clusters
be limited to Scala jobs only.
use project equalization, which forces all users to act under the same set of attributes, groups, and purposes with respect to their data access.
When data is read in Spark using an Immuta policy-enforced plan, the masking and redaction of rows is performed at the leaf level of the physical Spark plan, so a policy such as "Mask using hashing the column social_security_number for everyone" would be implemented as an expression on a project node right above the FileSourceScanExec/LeafExec node at the bottom of the plan. This process prevents raw data from being shuffled in a Spark application and, consequently, from ending up in SPARK_LOCAL_DIR.
This policy implementation coupled with an equalized project guarantees that data being dropped into SPARK_LOCAL_DIR will have policies enforced and that those policies will be homogeneous for all users on the cluster. Since each user will have access to the same data, if they attempt to manually access other users' cached/spilled data, they will only see what they have access to via equalized permissions on the cluster. If project equalization is not turned on, users could dig through that directory and find data from another user with heightened access, which would result in a data leak.
To require that Scala clusters be used in equalized projects and avoid the risk described above, change the immuta.spark.require.equalization value to true in your Immuta configuration file when you spin up Scala clusters:
Once this configuration is complete, users on the cluster will need to switch to an Immuta equalized project before running a job. (Remember that when working under an Immuta Project, only tables within that project can be seen.) Once the first job is run using that equalized project, all subsequent jobs, no matter the user, must also be run under that same equalized project. If you need to change a cluster's project, you must restart the cluster.
This page describes how the Security Manager is disabled for Databricks clusters that do not allow R or Scala code to be executed. Databricks Administrators should place the desired configuration in the Spark environment variables (recommended) or immuta_conf.xml (not recommended).
The Immuta Security Manager is an essential element of the Databricks Spark deployment that ensures users can't perform unauthorized actions when using Scala and R, since those languages have features that allow users to circumvent policies without the Security Manager enabled. However, the Security Manager must inspect the call stack every time a permission check is triggered, which adds overhead to queries. To improve Immuta's query performance on Databricks, Immuta disables the Security Manager when Scala and R are not being used.
The cluster init script checks the cluster’s configuration and automatically removes the Security Manager configuration when
spark.databricks.repl.allowedlanguages is a subset of {python, sql}
IMMUTA_SPARK_DATABRICKS_PY4J_STRICT_ENABLED is true
When the cluster is configured this way, Immuta can rely on Databricks' process isolation and Py4J security to prevent user code from performing unauthorized actions.
Note: Immuta still expects the spark.driver.extraJavaOptions and spark.executor.extraJavaOptions to be set and pointing at the Security Manager.
Beyond disabling the Security Manager, Immuta will skip several startup tasks that are required to secure the cluster when Scala and R are configured, and fewer permission checks will occur on the Driver and Executors in the Databricks cluster, reducing overhead and improving performance.
There are still cases that require the Security Manager; in those instances, Immuta creates a fallback Security Manager to check the code path, so the IMMUTA_INIT_ALLOWED_CALLING_CLASSES_URI environment variable must always point to a valid calling class file.
Databricks’ dbutils.fs is blocked by their PY4J security; therefore, it can’t be used to access scratch paths.
CDF shows the row-level changes between versions of a Delta table. The changes displayed include row data and metadata that indicates whether the row was inserted, deleted, or updated.
Immuta does not support applying policies to the changed data, and the CDF cannot be read for data source tables if the user does not have access to the raw data in Databricks. However, the CDF can be read if the querying user is allowed to read the raw data and one of the following statements is true:
the table is in the current workspace,
the table is in a scratch path,
non-Immuta reads are enabled AND the table does not intersect with a workspace under which the current user is not acting, or
non-Immuta reads are enabled AND the table is not part of an Immuta data source.
There are no configuration changes necessary to use this feature.
Immuta does not support reading changes in streaming queries.
This page provides an overview of Immuta's Databricks Trusted Libraries feature and support of Notebook-Scoped Libraries on Machine Learning Clusters.
The Immuta security manager blocks users from executing code that could allow them to gain access to sensitive data by only allowing select code paths to access sensitive files and methods. These select code paths provide Immuta's code access to sensitive resources while blocking end users from these sensitive resources directly.
Similarly, when users install third-party libraries those libraries will be denied access to sensitive resources by default. However, cluster administrators can specify which of the installed Databricks libraries should be trusted by Immuta.
The trusted libraries feature allows Databricks cluster administrators to avoid Immuta security manager errors when using third-party libraries. An administrator can specify an installed library as "trusted," which will enable that library's code to bypass the Immuta security manager. Contact your Immuta support professional for custom security configurations for your libraries.
This feature does not impact Immuta's ability to apply policies; trusting a library only allows code through what previously would have been blocked by the security manager.
Security vulnerability
Using this feature could create a security vulnerability, depending on the third-party library. For example, if a library exposes a public method named readProtectedFile that displays the contents of a sensitive file, then trusting that library would allow end users access to that file. Work with your Immuta support professional to determine if the risk does not apply to your environment or use case.
Databricks Libraries API: Installing trusted libraries outside of the Databricks Libraries API (e.g., ADD JAR ...) is not supported.
The following types of libraries are supported when installing a third-party library using the Databricks UI or the Databricks Libraries API:
Library source is Upload, DBFS or DBFS/S3 and the Library Type is Jar.
Library source is Maven.
Databricks installs libraries right after a cluster has started, but there is no guarantee that library installation will complete before a user's code is executed. If a user executes code before a trusted library installation has completed, Immuta will not be able to identify the library as trusted. This can be solved by either
waiting for library installation to complete before running any third-party library commands or
executing a Spark query. This will force Immuta to wait for any trusted Immuta libraries to complete installation before proceeding.
When installing a library using Maven as a library source, Databricks will also install any transitive dependencies for the library. However, those transitive dependencies are installed behind the scenes and will not appear as installed libraries in either the Databricks UI or using the Databricks Libraries API. Only libraries specifically listed in the IMMUTA_SPARK_DATABRICKS_TRUSTED_LIB_URIS environment variable will be trusted by Immuta, which does not include installed transitive dependencies. This effectively means that any code paths that include a class from a transitive dependency but do not include a class from a trusted third-party library can still be blocked by the Immuta security manager. For example, if a user installs a trusted third-party library that has a transitive dependency of a file-util library, the user will not be able to directly use the file-util library to read a sensitive file that is normally protected by the Immuta security manager.
In many cases, it is not a problem if dependent libraries aren't trusted because code paths where the trusted library calls down into dependent libraries will still be trusted. However, if the dependent library needs to be trusted, there is a workaround:
Add the transitive dependency jar paths to the IMMUTA_SPARK_DATABRICKS_TRUSTED_LIB_URIS environment variable. In the driver log4j logs, Databricks outputs the source jar locations when it installs transitive dependencies. In the cluster driver logs, look for a log message similar to the following:
In the above example, where slf4j is the transitive dependency, you would add the path dbfs:/FileStore/jars/maven/org/slf4j/slf4j-api-1.7.25.jar to the IMMUTA_SPARK_DATABRICKS_TRUSTED_LIB_URIS environment variable and restart your cluster.
In case of failure, check the driver logs for details. Some possible causes of failure include
One of the Immuta configured trusted library URIs does not point to a Databricks library. Check that you have configured the correct URI for the Databricks library.
For trusted Maven artifacts, the URI must follow this format: maven:/group.id:artifact-id:version.
Databricks failed to install a library. Any Databricks library installation errors will appear in the Databricks UI under the Libraries tab.
For details about configuring trusted libraries, navigate to the installation guide.
Users on Databricks runtimes 8+ can manage notebook-scoped libraries with %pip commands.
However, this functionality differs from Immuta's trusted libraries feature, and Python libraries are still not supported as trusted libraries. The Immuta Security Manager will deny the code of libraries installed with %pip access to sensitive resources.
No additional configuration is needed to enable this feature. Users only need to be running on clusters with DBR 8+.
Cluster 1
9.1
Unavailable
Unavailable
Cluster 2
10.4
Unavailable
Unavailable
Cluster 3
11.3
Unavailable
Cluster 4
11.3
Cluster 5
11.3
Databricks metastore magic allows you to migrate your data from the Databricks legacy Hive metastore to the Unity Catalog metastore while protecting data and maintaining your current processes in a single Immuta instance.
Databricks metastore magic is for customers who intend to use the Databricks Unity Catalog integration, but they would like to protect tables in the Hive metastore.
Unity Catalog support is enabled in Immuta.
Databricks has two built-in metastores that contain metadata about your tables, views, and storage credentials:
Legacy Hive metastore: Created at the workspace level. This metastore contains metadata of the configured tables in that workspace available to query.
Unity Catalog metastore: Created at the account level and is attached to one or more Databricks workspaces. This metastore contains metadata of the configured tables available to query. All clusters on that workspace use the configured metastore and all workspaces that are configured to use a single metastore share those tables.
Databricks allows you to use the legacy Hive metastore and the Unity Catalog metastore simultaneously. However, Unity Catalog does not support controls on the Hive metastore, so you must attach a Unity Catalog metastore to your workspace and move existing databases and tables to the attached Unity Catalog metastore to use the governance capabilities of Unity Catalog.
Immuta's Databricks Spark integration and Unity Catalog integration enforce access controls on the Hive and Unity Catalog metastores, respectively. However, because these metastores have two distinct security models, users were discouraged from using both in a single Immuta instance before metastore magic; the Databricks Spark integration and Unity Catalog integration were unaware of each other, so using both concurrently caused undefined behavior.
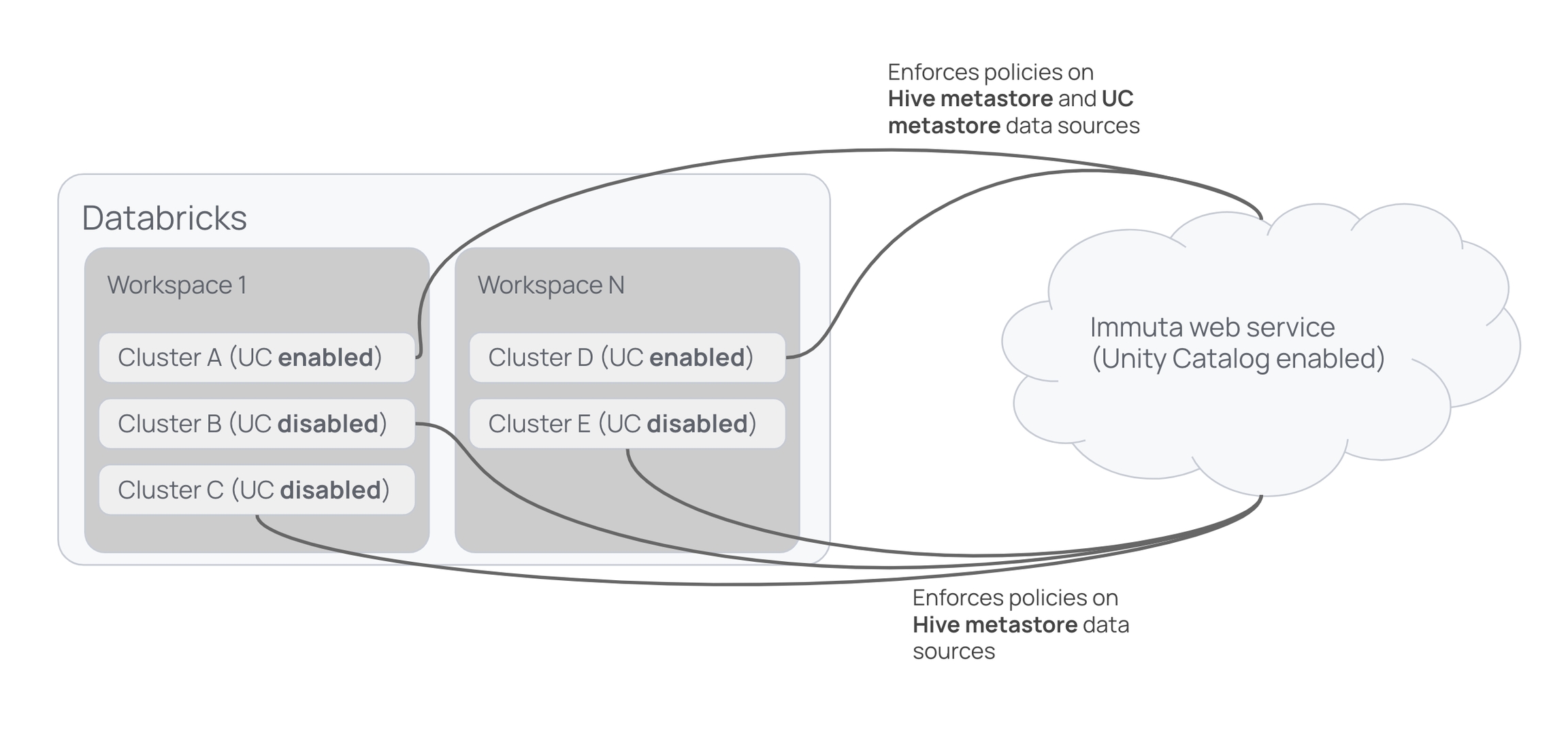
Metastore magic reconciles the distinct security models of the legacy Hive metastore and the Unity Catalog metastore, allowing you to use multiple metastores (specifically, the Hive metastore or AWS Glue Data Catalog alongside Unity Catalog metastores) within a Databricks workspace and single Immuta instance and keep policies enforced on all your tables as you migrate them. The diagram below shows Immuta enforcing policies on registered tables across workspaces.
In clusters A and D, Immuta enforces policies on data sources in each workspace's Hive metastore and in the Unity Catalog metastore shared by those workspaces. In clusters B, C, and E (which don't have Unity Catalog enabled in Databricks), Immuta enforces policies on data sources in the Hive metastores for each workspace.
With metastore magic, the Databricks Spark integration enforces policies only on data in the Hive metastore, while the Unity Catalog integration enforces policies on tables in the Unity Catalog metastore. The table below illustrates this policy enforcement.
Hive metastore
Unity Catalog metastore
To enforce plugin-based policies on Hive metastore tables and Unity Catalog native controls on Unity Catalog metastore tables, enable the Databricks Spark integration and the Databricks Unity Catalog integration. Note that some Immuta policies are not supported in the Databricks Unity Catalog integration. See the Databricks Unity Catalog integration reference guide for details.
Databricks SQL cannot run the Databricks Spark plugin to protect tables, so Hive metastore data sources will not be policy enforced in Databricks SQL.
To enforce policies on data sources in Databricks SQL, use Hive metastore table access controls to manually lock down Hive metastore data sources and the Databricks Unity Catalog integration to protect tables in the Unity Catalog metastore. Table access control is enabled by default on SQL warehouses, and any Databricks cluster without the Immuta plugin must have table access control enabled.
The table below outlines the integrations supported for various Databricks cluster configurations. For example, the only integration available to enforce policies on a cluster configured to run on Databricks Runtime 9.1 is the Databricks Spark integration.
Cluster 1
9.1
Unavailable
Unavailable
Cluster 2
10.4
Unavailable
Unavailable
Cluster 3
11.3
Unavailable
Cluster 4
11.3
Cluster 5
11.3
Legend:
Delta Lake API reference guide
When using Delta Lake, the API does not go through the normal Spark execution path. This means that Immuta's Spark extensions do not provide protection for the API. To solve this issue and ensure that Immuta has control over what a user can access, the Delta Lake API is blocked.
Spark SQL can be used instead to give the same functionality with all of Immuta's data protections.
Below is a table of the Delta Lake API with the Spark SQL that may be used instead.
See here for a complete list of the .
When a table is created in a native workspace, you can merge a different Immuta data source from that workspace into that table you created.
Create a table in the native workspace.
Create a temporary view of the Immuta data source you want to merge into that table.
Use that temporary view as the data source you add to the project workspace.
Run the following command:
/
/
The feature or integration is enabled.
The feature or integration is disabled.
DeltaTable.convertToDelta
CONVERT TO DELTA parquet./path/to/parquet/
DeltaTable.delete
DELETE FROM [table_identifier delta./path/to/delta/] WHERE condition
DeltaTable.generate
GENERATE symlink_format_manifest FOR TABLE [table_identifier delta./path/to/delta]
DeltaTable.history
DESCRIBE HISTORY [table_identifier delta./path/to/delta] (LIMIT x)
DeltaTable.merge
MERGE INTO
DeltaTable.update
UPDATE [table_identifier delta./path/to/delta/] SET column = valueWHERE (condition)
DeltaTable.vacuum
VACUUM [table_identifier delta./path/to/delta]
In addition to supporting direct file reads through workspace and scratch paths, Immuta allows direct file reads in Spark for file paths. As a result, users who prefer to interact with their data using file paths or who have existing workflows revolving around file paths can continue to use these workflows without rewriting those queries for Immuta.
When reading from a path in Spark, the Immuta Databricks Spark plugin queries the Immuta Web Service to find Databricks data sources for the current user that are backed by data from the specified path. If found, the query plan maps to the Immuta data source and follows existing code paths for policy enforcement.
Users can read data from individual parquet files in a sub-directory and partitioned data from a sub-directory (or by using a where predicate). Use the tabs below to view examples of reading data using these methods.
To read from an individual file, load a partition file from a sub-directory:
To read partitioned data from a sub-directory, load a parquet partition from a sub-directory:
Alternatively, load a parquet partition using a where predicate:
Direct file reads for Immuta data sources only apply to table-backed Immuta data sources, not data sources created from views or queries.
If more than one data source has been created for a path, Immuta will use the first valid data source it finds. It is therefore not recommended to use this integration when more than one data source has been created for a path.
In Databricks, multiple input paths are supported as long as they belong to the same data source.
CSV-backed tables are not currently supported.
Loading a delta partition from a sub-directory is not recommended by Spark and is not supported in Immuta. Instead, use a where predicate: