Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
This guide details the manual installation method for enabling native access to Databricks with Immuta policies enforced. Before proceeding, ensure your Databricks workspace, instance, and permissions meet the guidelines outlined in the Installation Introduction.
Databricks Unity Catalog: If Unity Catalog is enabled in a Databricks workspace, you must use an Immuta cluster policy when you set up the integration to create an Immuta-enabled cluster.
immuta_conf.xml is no longer required
The immuta_conf.xml file that was previously used to configure the native Databricks Spark integration is no longer required to install Immuta, so it is no longer staged as a deployment artifact. However, you can use these snippets if you wish to deploy an immuta_conf.xml file to set properties.
The required Immuta base URL and Immuta system API key properties, along with any other valid properties, can still be specified as Spark environment variables or in the optional immuta_conf.xml file. As before, if the same property is specified in both locations, the Spark environment variable takes precedence.
If you have an existing immuta_conf.xml file, you can continue using it. However, it's recommended that you delete any default properties from the file that you have not explicitly overridden, or remove the file completely and rely on Spark environment variables. Either method will ensure that any property defaults changed in upcoming Immuta releases are propagated to your environment.
Spark Version
Use Spark 2 with Databricks Runtime prior to 7.x. Use Spark 3 with Databricks Runtime 7.x or later. Attempting to use an incompatible jar and Databricks Runtime will fail.
Navigate to the Immuta archives page. If you are prompted to log in and need basic authentication credentials, contact your Immuta support professional.
Navigate to the Databricks folder for your Immuta version. Ex: https://archives.immuta.com/hadoop/databricks/2024.3.5/.
Download the .jar file (Immuta plugin) as well as the other scripts listed below, which will load the plugin at cluster startup.
The immuta-benchmark-suite.dbc is a collection of notebooks packaged as a .dbc file. After you have added cluster policies to your cluster, you can import this file into Databricks to run performance tests and compare a regular Databricks cluster to one protected by Immuta. Detailed instructions are available in the first notebook, which will require an Immuta and non-Immuta cluster to generate test data and perform queries. Note: Use Spark 2 with Databricks Runtime prior to 7.x. Use Spark 3 with Databricks Runtime 7.x or later. Attempting to use an incompatible jar and Databricks Runtime will fail.
Specify the following properties as Spark environment variables or in the optional immuta_conf.xml file. If the same property is specified in both locations, the Spark environment variable takes precedence. The variable names are the config names in all upper case with _ instead of .. For example, to set the value of immuta.base.url via an environment variable, you would set the following in the Environment Variables section of cluster configuration: IMMUTA_BASE_URL=https://immuta.mycompany.com
immuta.system.api.key: Obtain this value from the Immuta Configuration UI under HDFS > System API Key. You will need to be a user with the APPLICATION_ADMIN role to complete this action.
immuta.base.url: The full URL for the target Immuta tenant Ex: https://immuta.mycompany.com.
immuta.user.mapping.iamid: If users authenticate to Immuta using an IAM different from Immuta's built-in IAM, you need to update the configuration file to reflect the ID of that IAM. The IAM ID is shown within the Immuta App Settings page within the Identity Management section. See Databricks to Immuta User Mapping for more details.
Environment variables with Google Cloud Platform
Do not use environment variables to set sensitive properties when using Google Cloud Platform. Set them directly in immuta_conf.xml.
Generating a key will destroy any previously generated HDFS keys. This will cause previously integrated HDFS systems to lose access to your Immuta console. The key will only be shown once when generated.
When configuring the Databricks cluster, a path will need to be provided to each of the artifacts downloaded/created in the previous step. To do this, those artifacts must be hosted somewhere that your Databricks instance can access. The following methods can be used for this step:
Host files in AWS/S3 and provide access by the cluster
Host files in Azure ADL Gen 1 or Gen 2 and provide access by the cluster
Host files on an HTTPS server accessible by the cluster
Host files in DBFS (Not recommended for production)
These artifacts will be downloaded to the required location within the clusters file-system by the init script downloaded in the previous step. In order for the init script to find these files, a URI will have to be provided through environment variables configured on the cluster. Each method's URI structure and setup is explained below.
URI Structure: s3://[bucket]/[path]
Create an instance profile for clusters by following Databricks documentation.
Upload the configuration file, JSON file, and JAR file to an S3 bucket that the role from step 1 has access to.
If you wish to authenticate using access keys, add the following items to the cluster's environment variables:
If you've assumed a role and received a session token, that can be added here as well:
URI Structure: abfs(s)://[container]@[account].dfs.core.windows.net/[path]
Upload the configuration file, JSON file, and JAR file to an ADL gen 2 blob container.
Environment Variables:
If you want to authenticate using an account key, add the following to your cluster's environment variables:
If you want to authenticate using an Azure SAS token, add the following to your cluster's environment variables:
URI Structure: adl://[account].azuredatalakestore.net/[path]
Upload the configuration file, JSON file, and JAR file to ADL gen 1.
Environment Variables:
If authenticating as a Microsoft Entra ID user,
If authenticating using a service principal,
URI Structure: http(s)://[host](:port)/[path]
Artifacts are available for download from Immuta using basic authentication. Your basic authentication credentials can be obtained from your Immuta support professional.
DBFS does not support access control
Any Databricks user can access DBFS via the Databricks command line utility. Files containing sensitive materials (such as Immuta API keys) should not be stored there in plain text. Use other methods described herein to properly secure such materials.
URI Structure: dbfs:/[path]
Upload the artifacts directly to DBFS using the Databricks CLI.
Since any user has access to everything in DBFS:
The artifacts can be stored anywhere in DBFS.
It's best to have a cluster-specific place for your artifacts in DBFS if you are testing to avoid overwriting or reusing someone else's artifacts accidentally.
It is important that non-administrator users on an Immuta-enabled Databricks cluster do not have access to view or modify Immuta configuration or the immuta-spark-hive.jar file, as this would potentially pose a security loophole around Immuta policy enforcement. Therefore, use Databricks secrets to apply environment variables to an Immuta-enabled cluster in a secure way.
Databricks secrets can be used in the Environment Variables configuration section for a cluster by referencing the secret path rather than the actual value of the environment variable. For example, if a user wanted to make the following value secret
they could instead create a Databricks secret and reference it as the value of that variable. For instance, if the secret scope my_secrets was created, and the user added a secret with the key my_secret_env_var containing the desired sensitive environment variable, they would reference it in the Environment Variables section:
Then, at runtime, {{secrets/my_secrets/my_secret_env_var}} would be replaced with the actual value of the secret if the owner of the cluster has access to that secret.
Best practice: Replace sensitive variables with secrets
Immuta recommends that any sensitive environment variables listed below in the various artifact deployment instructions be replaced with secrets.
Cluster creation in an Immuta-enabled organization or Databricks workspace should be limited to administrative users to avoid allowing users to create non-Immuta enabled clusters.
Create a cluster in Databricks by following the Databricks documentation.
Select the Custom Access mode.
Opt to adjust the Autopilot Options and Worker Type settings. The default values provided here may be more than what is necessary for non-production or smaller use-cases. To reduce resource usage you can enable/disable autoscaling, limit the size and number of workers, and set the inactivity timeout to a lower value.
In the Advanced Options section, click the Instances tab.
IAM Role (AWS ONLY): Select the instance role you created for this cluster. (For access key authentication, you should instead use the environment variables listed in the AWS section.)
Click the Spark tab. In Spark Config field, add your configuration.
Cluster Configuration Requirements:
In the Environment Variables section, add the environment variables necessary for your configuration. Remember that these variables should be protected with Databricks secrets as mentioned above.
Click the Init Scripts tab and set the following configurations:
Destination: Specify the service you used to host the Immuta artifacts.
File Path: Specify the full URI to the immuta_cluster_init_script.sh.
Add the new key/value to the configuration.
Click the Permissions tab and configure the following setting:
Who has access: Users or groups will need to have the permission Can Attach To to execute queries against Immuta configured data sources.
(Re)start the cluster.
As mentioned in the "Environment Variables" section of the cluster configuration, there may be some cases where it is necessary to add sensitive configuration to SparkSession.sparkContext.hadoopConfiguration in order to read the data composing Immuta data sources.
As an example, when accessing external tables stored in Azure Data Lake Gen 2, Spark must have credentials to access the target containers/filesystems in ADLg2, but users must not have access to those credentials. In this case, an additional configuration file may be provided with a storage account key that the cluster may use to access ADLg2.
To use an additional Hadoop configuration file, you will need to set the IMMUTA_INIT_ADDITIONAL_CONF_URI environment variable referenced in the Create and configure the cluster section to be the full URI to this file.
The additional configuration file looks very similar to the Immuta Configuration file referenced above. Some example configuration files for accessing different storage layers are below.
IAM role for S3 access
S3 can also be accessed using an IAM role attached to the cluster. See the Databricks documentation for more details.
ADL prefix: Prior to Databricks Runtime version 6, the following configuration items should have a prefix of dfs.adls rather than fs.adl.
Register Databricks securables in Immuta.
When the Immuta enabled Databricks cluster has been successfully started, users will see a new database labeled "immuta". This database is the virtual layer provided to access data sources configured within the connected Immuta instance.
Before users can query an Immuta data source, an administrator must give the user Can Attach To permissions on the cluster and GRANT the user access to the immuta database.
The following SQL query can be run as an administrator within a journal to give the user access to "Immuta":
Below are example queries that can be run to obtain data from an Immuta-configured data source. Because Immuta supports raw tables in Databricks, you do not have to use Immuta-qualified table names in your queries like the first example. Instead, you can run queries like the second example, which does not reference the immuta database.
See the Databricks Data Source Creation guide for a detailed walkthrough.
By default, the IAM used to map users between Databricks and Immuta is the BIM (Immuta's internal IAM). The Immuta Spark plugin will check the Databricks username against the username within the BIM to determine access. For a basic integration, this means the users email address in Databricks and the connected Immuta tenant must match.
It is possible within Immuta to have multiple users share the same username if they exist within different IAMs. In this case, the cluster can be configured to lookup users from a specified IAM. To do this, the value of immuta.user.mapping.iamid created and hosted in the previous steps must be updated to be the targeted IAM ID configured within the Immuta tenant. The IAM ID can be found on the App Settings page. Each Databricks cluster can only be mapped to one IAM.
If a Databricks cluster needs to be manually updated to reflect changes in the Immuta init script or cluster policies, you can remove and set up your integration again to get the updated policies and init script.
Log in to Immuta as an Application Admin.
Click the App Settings icon in the left sidebar and scroll to the Integration Settings section.
Your existing Databricks Spark integration should be listed here; expand it and note the configuration values. Now select Remove to remove your integration.
Click Add Native Integration and select Databricks Integration to add a new integration.
Enter your Databricks Spark integration settings again as configured previously.
Click Add Native Integration to add the integration, and then select Configure Cluster Policies to set up the updated cluster policies and init script.
Select the cluster policies you wish to use for your Immuta-enabled Databricks clusters.
Automatically push cluster policies and the init script (recommended) or manually update your cluster policies.
Automatically push cluster policies
Select Automatically Push Cluster Policies and enter your privileged Databricks access token. This token must have privileges to write to cluster policies.
Select Apply Policies to push the cluster policies and init script again.
Click Save and Confirm to deploy your changes.
Manually update cluster policies
Download the init script and the new cluster policies to your local computer.
Click Save and Confirm to save your changes in Immuta.
Log in to your Databricks workspace with your administrator account to set up cluster policies.
Get the path you will upload the init script (`immuta_cluster_init_script_proxy.sh`) to by opening one of the cluster policy `.json` files and looking for the `defaultValue` of the field `init_scripts.0.dbfs.destination`. This should be a DBFS path in the form of `dbfs:/immuta-plugin/hostname/immuta_cluster_init_script_proxy.sh`.
Click Data in the left pane to upload your init script to DBFS to the path you found above.
To find your existing cluster policies you need to update, click Compute in the left pane and select the Cluster policies tab.
Edit each of these cluster policies that were configured before and overwrite the contents of the JSON with the new cluster policy JSON you downloaded.
Restart any Databricks clusters using these updated policies for the changes to take effect.
This guide details the simplified installation method for enabling native access to Databricks with Immuta policies enforced.
Ensure your Databricks workspace, instance, and permissions meet the guidelines outlined in the before you begin.
Databricks Unity Catalog: If Unity Catalog is enabled in a Databricks workspace, you must use an Immuta cluster policy when you set up the integration to create an Immuta-enabled cluster.
Log in to Immuta and click the App Settings icon in the left sidebar.
Scroll to the System API Key subsection under HDFS and click Generate Key.
Click Save and then Confirm.
Scroll to the Integration Settings section.
Click + Add Native Integration and select Databricks Integration from the dropdown menu.
Complete the Hostname field.
Enter a Unique ID for the integration. By default, your Immuta tenant URL populates this field. This ID is used to tie the set of cluster policies to your Immuta tenant and allows multiple Immuta tenants to access the same Databricks workspace without cluster policy conflicts.
Select your configured Immuta IAM from the dropdown menu.
Choose one of the following options for your data access model:
Protected until made available by policy: All tables are hidden until a user is permissioned through an Immuta policy. This is how most databases work and assumes least privileged access and also means you will have to register all tables with Immuta.
Available until protected by policy: All tables are open until explicitly registered and protected by Immuta. This makes a lot of sense if most of your tables are non-sensitive and you can pick and choose which to protect.
Select the Storage Access Type from the dropdown menu.
Opt to add any Additional Hadoop Configuration Files.
Click Add Native Integration.
Several cluster policies are available on the App Settings page when configuring this integration:
Click a link above to read more about each of these cluster policies before continuing with the tutorial.
Click Configure Cluster Policies.
Select one or more cluster policies in the matrix by clicking the Select button(s).
Opt to check the Enable Unity Catalog checkbox to generate cluster policies that will enable Unity Catalog on your cluster. This option is only available when Databricks runtime 11.3 is selected.
Opt to make changes to these cluster policies by clicking Additional Policy Changes and editing the text field.
Use one of the two Installation Types described below to apply the policies to your cluster:
Automatically push cluster policies: This option allows you to automatically push the cluster policies to the configured Databricks workspace. This will overwrite any cluster policy templates previously applied to this workspace.
Select the Automatically Push Cluster Policies radio button.
Enter your Admin Token. This token must be for a user who can create cluster policies in Databricks.
Click Apply Policies.
Manually push cluster policies: Enabling this option will allow you to manually push the cluster policies to the configured Databricks workspace. There will be various files to download and manually push to the configured Databricks workspace.
Select the Manually Push Cluster Policies radio button.
Click Download Init Script.
Follow the steps in the Instructions to upload the init script to DBFS section.
Click Download Policies, and then manually add these Cluster Policies in Databricks.
Opt to click the Download the Benchmarking Suite to compare a regular Databricks cluster to one protected by Immuta. Detailed instructions are available in the first notebook, which will require an Immuta and non-Immuta cluster to generate test data and perform queries.
Click Close, and then click Save and Confirm.
In the Policy dropdown, select the Cluster Policies you pushed or manually added from Immuta.
Select the Custom Access mode.
Opt to adjust Autopilot Options and Worker Type settings: The default values provided here may be more than what is necessary for non-production or smaller use-cases. To reduce resource usage you can enable/disable autoscaling, limit the size and number of workers, and set the inactivity timeout to a lower value.
Opt to configure the Instances tab in the Advanced Options section:
Click Create Cluster.
Before users can query an Immuta data source, an administrator must give the user Can Attach To permissions on the cluster.
This page contains references to the term whitelist, which Immuta no longer uses. When the term is removed from the software, it will be removed from this page.
Databricks instance: Premium tier workspace and
Databricks instance has network level access to Immuta tenant
Access to
Permissions and access to download (outside Internet access) or transfer files to the host machine
Recommended Databricks Workspace Configurations:
Note: Azure Databricks authenticates users with Microsoft Entra ID. Be sure to configure your Immuta tenant with an IAM that uses the same user ID as does Microsoft Entra ID. Immuta's Spark security plugin will look to match this user ID between the two systems. See this for details.
Use the table below to determine which version of Immuta supports your Databricks Runtime version:
The table below outlines the integrations supported for various Databricks cluster configurations. For example, the only integration available to enforce policies on a cluster configured to run on Databricks Runtime 9.1 is the Databricks Spark integration.
Legend:
Immuta supports the Custom access mode.
Supported Languages:
Python
SQL
R (requires advanced configuration; work with your Immuta support professional to use R)
Scala (requires advanced configuration; work with your Immuta support professional to use Scala)
Users who can read raw tables on-cluster
If a Databricks Admin is tied to an Immuta account, they will have the ability to read raw tables on-cluster.
If a Databricks user is listed as an "ignored" user, they will have the ability to read raw tables on-cluster. Users can be added to the immuta.spark.acl.whitelist configuration to become ignored users.
The Immuta Databricks Spark integration injects an Immuta plugin into the SparkSQL stack at cluster startup. The Immuta plugin creates an "immuta" database that is available for querying and intercepts all queries executed against it. For these queries, policy determinations will be obtained from the connected Immuta tenant and applied before returning the results to the user.
The Databricks cluster init script provided by Immuta downloads the Immuta artifacts onto the target cluster and puts them in the appropriate locations on local disk for use by Spark. Once the init script runs, the Spark application running on the Databricks cluster will have the appropriate artifacts on its CLASSPATH to use Immuta for policy enforcement.
The cluster init script uses environment variables in order to
Determine the location of the required artifacts for downloading.
Authenticate with the service/storage containing the artifacts.
Note: Each target system/storage layer (HTTPS, for example) can only have one set of environment variables, so the cluster init script assumes that any artifact retrieved from that system uses the same environment variables.
There are two installation options for Databricks. Click a link below to navigate to a tutorial for your chosen method:
Adding the integration on the App Settings page.
Downloading or automatically pushing cluster policies to your Databricks workspace.
Creating or restarting your cluster.
Downloading and configuring Immuta artifacts.
Staging Immuta artifacts somewhere the cluster can read from during its startup procedures.
Protecting Immuta environment variables with Databricks Secrets.
Creating and configuring the cluster to start with the init script and load Immuta into its SparkSQL environment.
For easier debugging of the Immuta Databricks installation, enable cluster init script logging. In the cluster page in Databricks for the target cluster, under Advanced Options -> Logging, change the Destination from NONE to DBFS and change the path to the desired output location. Note: The unique cluster ID will be added onto the end of the provided path.
For debugging issues between the Immuta web service and Databricks, you can view the Spark UI on your target Databricks cluster. On the cluster page, click the Spark UI tab, which shows the Spark application UI for the cluster. If you encounter issues creating Databricks data sources in Immuta, you can also view the JDBC/ODBC Server portion of the Spark UI to see the result of queries that have been sent from Immuta to Databricks.
The Validation and Debugging Notebook (immuta-validation.ipynb) is packaged with other Databricks release artifacts (for manual installations), or it can be downloaded from the App Settings page when configuring native Databricks through the Immuta UI. This notebook is designed to be used by or under the guidance of an Immuta Support Professional.
Import the notebook into a Databricks workspace by navigating to Home in your Databricks instance.
Click the arrow next to your name and select Import.
Once you have executed commands in the notebook and populated it with debugging information, export the notebook and its contents by opening the File menu, selecting Export, and then selecting DBC Archive.
Generally, Immuta prevents users from seeing data unless they are explicitly given access, which blocks access to raw sources in the underlying databases. However, in some native patterns (such as Snowflake), Immuta adds views to allow users access to Immuta sources but does not impede access to preexisting sources in the underlying database. Therefore, if a user had access in Snowflake to a table before Immuta was installed, they would still have access to that table after.
Unlike the example above, Databricks non-admin users will only see sources to which they are subscribed in Immuta, and this can present problems if organizations have a data lake full of non-sensitive data and Immuta removes access to all of it. The Limited Enforcement Scope feature addresses this challenge by allowing Immuta users to access any tables that are not protected by Immuta (i.e., not registered as a data source or a table in a native workspace). Although this is similar to how privileged users in Databricks operate, non-privileged users cannot bypass Immuta controls.
This feature is composed of two configurations:
Allowing non-Immuta reads: Immuta users with regular (unprivileged) Databricks roles may SELECT from tables that are not registered in Immuta.
Allowing non-Immuta writes: Immuta users with regular (unprivileged) Databricks roles can run DDL commands and data-modifying commands against tables or spaces that are not registered in Immuta.
Additionally, Immuta supports auditing all queries run on a Databricks cluster, regardless of whether users touch Immuta-protected data or not. To configure Immuta to do so, navigate to the .
Non-Immuta reads
This setting does not allow reading data directly with commands like spark.read.format("x"). Users are still required to read data and query tables using Spark SQL.
When non-Immuta reads are enabled, Immuta users will see all databases and tables when they run show databases and/or show tables. However, this does not mean they will be able to query all of them.
Enable non-Immuta Reads by setting this configuration in the Spark environment variables (recommended) or immuta_conf.xml (not recommended):
Opt to adjust the cache duration by changing the default value in the Spark environment variables (recommended) or immuta_conf.xml (not recommended). (Immuta caches whether a table has been exposed as an Immuta source to improve performance. The default caching duration is 1 hour.)
Non-Immuta writes
These non-protected tables/spaces have the same exposure as detailed in the read section, but with the distinction that users can write data directly to these paths.
With non-Immuta writes enabled, it will be possible for users on the cluster to mix any policy-enforced data they may have access to via any registered data sources in Immuta with non-Immuta data, and write the ensuing result to a non-Immuta write space where it would be visible to others. If this is not a desired possibility, the cluster should instead be configured to only use Immuta’s native workspaces.
Enable non-Immuta Writes by setting this configuration in the Spark environment variables (recommended) or immuta_conf.xml (not recommended):
Opt to adjust the cache duration by changing the default value in the Spark environment variables (recommended) or immuta_conf.xml (not recommended). (Immuta caches whether a table has been exposed as an Immuta source to improve performance. The default caching duration is 1 hour.)
Enable support for auditing all queries run on a Databricks cluster (regardless of whether users touch Immuta-protected data or not) by setting this configuration in the Spark environment variables (recommended) or immuta_conf.xml (not recommended):
The controls and default values associated with non-Immuta reads, non-Immuta writes, and audit functionality are outlined below.
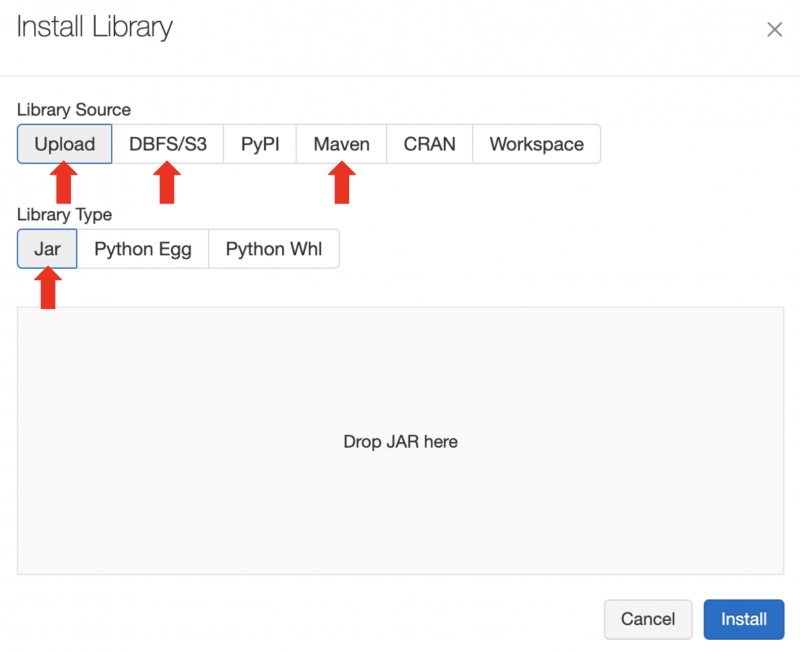
In the Databricks Clusters UI, install your third-party library .jar or Maven artifact with Library Source Upload, DBFS, DBFS/S3, or Maven. Alternatively, use the Databricks libraries API.
In the Databricks Clusters UI, add the IMMUTA_SPARK_DATABRICKS_TRUSTED_LIB_URIS property as a Spark environment variable and set it to your artifact's URI:
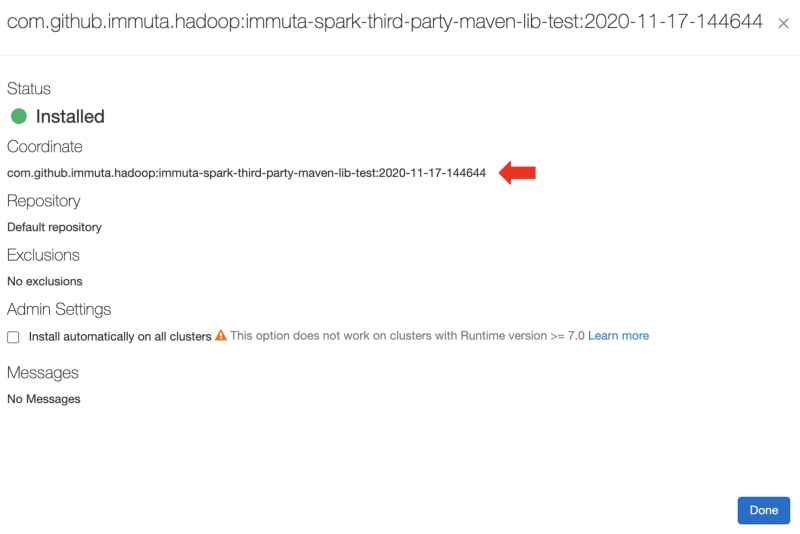
For Maven artifacts, the URI is maven:/<maven_coordinates>, where <maven_coordinates> is the Coordinates field found when clicking on the installed artifact on the Libraries tab in the Databricks Clusters UI. Here's an example of an installed artifact:
In this example, you would add the following Spark environment variable:
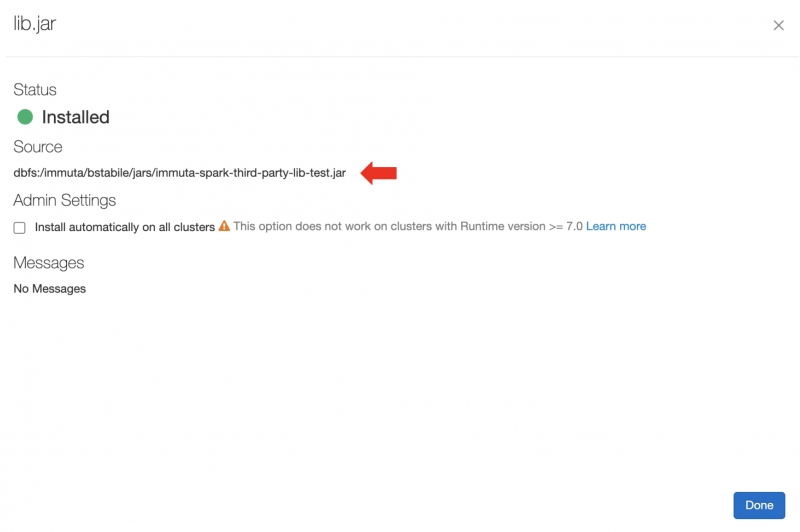
For jar artifacts, the URI is the Source field found when clicking on the installed artifact on the Libraries tab in the Databricks Clusters UI. For artifacts installed from DBFS or S3, this ends up being the original URI to your artifact. For uploaded artifacts, Databricks will rename your .jar and put it in a directory in DBFS. Here's an example of an installed artifact:
In this example, you would add the following Spark environment variable:
Once you've finished making your changes, restart the cluster.
Specifying more than one trusted library
To specify more than one trusted library, comma delimit the URIs:
Once the cluster is up, execute a command in a notebook. If the trusted library installation is successful, you should see driver log messages like this:
This page outlines how to access DBFS in Databricks for non-sensitive data. Databricks Administrators should place the desired configuration in the Spark environment variables (recommended) or the immuta_conf.xml file (not recommended).
This feature (provided by Databricks) mounts DBFS to the local cluster filesystem at /dbfs. Although disabled when using process isolation, this feature can safely be enabled if raw, unfiltered data is not stored in DBFS and all users on the cluster are authorized to see each other’s files. When enabled, the entirety of DBFS essentially becomes a scratch path where users can read and write files in /dfbs/path/to/my/file as though they were local files.
DBFS FUSE Mount limitation: This feature cannot be used in environments with E2 Private Link enabled.
For example,
In Python,
Note: This solution also works in R and Scala.
To enable the DBFS FUSE mount, set this configuration: immuta.spark.databricks.dbfs.mount.enabled=true.
Mounting a bucket
Users can that can also be accessed using the FUSE mount.
Mounting a bucket is a one-time action, and the mount will be available to all clusters in the workspace from that point on.
Mounting must be performed from a non-Immuta cluster.
Scratch paths will work when performing arbitrary remote filesystem operations with fs magic or Scala dbutils.fs functions. For example,
To support %fs magic and Scala DBUtils with scratch paths, configure
To use dbutils in Python, set this configuration: immuta.spark.databricks.py4j.strict.enabled=false.
This section illustrates the workflow for getting a file from a remote scratch path, editing it locally with Python, and writing it back to a remote scratch path.
Get the file from remote storage:
Make a copy if you want to explicitly edit localScratchFile, as it will be read-only and owned by root:
Write the new file back to remote storage:
This page outlines the configuration for setting up project UDFs, which allow users to set their current project in Immuta through Spark. For details about the specific functions available and how to use them, see the .
Use project UDFs in Databricks Spark
Currently, caches are not all invalidated outside of Databricks because Immuta caches information pertaining to a user's current project. Consequently, this feature should only be used in Databricks.
Immuta caches a mapping of user accounts and users' current projects in the Immuta Web Service and on-cluster. When users change their project with UDFs instead of the Immuta UI, Immuta invalidates all the caches on-cluster (so that everything changes immediately) and the cluster submits a request to change the project context to a web worker. Immediately after that request, another call is made to a web worker to refresh the current project.
To allow use of project UDFs in Spark jobs, raise the caching on-cluster and lower the cache timeouts for the Immuta Web Service. Otherwise, caching could cause dissonance among the requests and calls to multiple web workers when users try to change their project contexts.
Click the App Settings icon in the left sidebar and scroll to the HDFS Cache Settings section.
Lower the Cache TTL of HDFS user names (ms) to 0.
Click Save.
In the Spark environment variables section, set the IMMUTA_CURRENT_PROJECT_CACHE_TIMEOUT_SECONDS and IMMUTA_PROJECT_CACHE_TIMEOUT_SECONDS to high values (like 10000).
Note: These caches will be invalidated on cluster when a user calls immuta.set_current_project, so they can effectively be cached permanently on cluster to avoid periodically reaching out to the web service.
This guide illustrates how to run R and Scala spark-submit jobs on Databricks, including prerequisites and caveats.
Language support: R and Scala are supported, but require advanced configuration; work with your Immuta support professional to use these languages. Python spark-submit jobs are not supported by the Databricks Spark integration.
Using R in a notebook: Because of how some user properties are populated in Databricks, users should load the SparkR library in a separate cell before attempting to use any SparkR functions.
spark-submitBefore you can run spark-submit jobs on Databricks you must initialize the Spark session with the settings outlined below.
Initialize the Spark session by entering these settings into the R submit script immuta.spark.acl.assume.not.privileged="true" and spark.hadoop.immuta.databricks.config.update.service.enabled="false".
This will enable the R script to access Immuta data sources, scratch paths, and workspace tables.
Once the script is written, upload the script to a location in dbfs/S3/ABFS to give the Databricks cluster access to it.
spark submit JobTo create the R spark-submit job,
Go to the Databricks jobs page.
Create a new job, and select Configure spark-submit.
Set up the parameters:
Note: The path dbfs:/path/to/script.R can be in S3 or ABFS (on Azure Databricks), assuming the cluster is configured with access to that path.
Edit the cluster configuration, and change the Databricks Runtime to be a .
Configure the Environment Variables section as you normally would for an .
Before you can run spark-submit jobs on Databricks you must initialize the Spark session with the settings outlined below.
Configure the Spark session with immuta.spark.acl.assume.not.privileged="true" and spark.hadoop.immuta.databricks.config.update.service.enabled="false".
Note: Stop your Spark session (spark.stop()) at the end of your job or the cluster will not terminate.
The spark submit job needs to be launched using a different classloader which will point at the designated user JARs directory. The following Scala template can be used to handle launching your submit code using a separate classloader:
spark-submit JobTo create the Scala spark-submit job,
Build and upload your JAR to dbfs/S3/ABFS where the cluster has access to it.
Select Configure spark-submit, and configure the parameters:
Note: The fully-qualified class name of the class whose main function will be used as the entry point for your code in the --class parameter.
Note: The path dbfs:/path/to/code.jar can be in S3 or ABFS (on Azure Databricks) assuming the cluster is configured with access to that path.
Include IMMUTA_INIT_ADDITIONAL_JARS_URI=dbfs:/path/to/code.jar in the "Environment Variables" (where dbfs:/path/to/code.jar is the path to your jar) so that the jar is uploaded to all the cluster nodes.
The user mapping works differently from notebooks because spark-submit clusters are not configured with access to the Databricks SCIM API. The cluster tags are read to get the cluster creator and match that user to an Immuta user.
Privileged users (Databricks Admins and Whitelisted Users) must be tied to an Immuta user and given access through Immuta to access data through spark-submit jobs because the setting immuta.spark.acl.assume.not.privileged="true" is used.
There is an option of using the immuta.api.key setting with an Immuta API key generated on the Immuta profile page.
Currently when an API key is generated it invalidates the previous key. This can cause issues if a user is using multiple clusters in parallel, since each cluster will generate a new API key for that Immuta user. To avoid these issues, manually generate the API key in Immuta and set the immuta.api.key on all the clusters or use a specified job user for the submit job.
Create a cluster in Databricks by following the .
IAM Role (AWS ONLY): Select the instance role you created for this cluster. (For access key authentication, you should instead use the environment variables listed in the section.)
.
When the Immuta-enabled Databricks cluster has been successfully started, Immuta will create an immuta database, which allows Immuta to track Immuta-managed data sources separately from remote Databricks tables so that policies and other security features can be applied. However, users can query sources with their original database or table name without referencing the immuta database. Additionally, when configuring a Databricks cluster you can hide immuta from any calls to SHOW DATABASES so that users aren't misled or confused by its presence. For more details, see the page.
See the for a detailed walkthrough of creating Databricks data sources in Immuta.
Below are example queries that can be run to obtain data from an Immuta-configured data source. Because Immuta supports raw tables in Databricks, you do not have to use Immuta-qualified table names in your queries like the first example. Instead, you can run queries like the second example, which does not reference the .
The feature or integration is enabled.
The feature or integration is disabled.
See the for known limitations.
: The steps to enable the integration with this method include
: The steps to enable the integration with this method include
If your compliance requirements restrict users from changing projects within a session, you can block the use of Immuta's project UDFs on a Databricks Spark cluster. To do so, configure the immuta.spark.databricks.disabled.udfs option as described on the .
Edit the cluster configuration, and change the Databricks Runtime to a .
11.3 LTS
2023.1 and newer
10.4 LTS
2022.2.x and newer
7.3 LTS 9.1 LTS
2021.5.x and newer
Hiding the database does not disable access to it
Queries can still be performed against tables in the immuta database using the Immuta-qualified table name (e.g., immuta.my_schema_my_table) regardless of whether or not this feature is enabled.
The immuta database on Immuta-enabled clusters allows Immuta to track Immuta-managed data sources separately from remote Databricks tables so that policies and other security features can be applied. However, Immuta supports raw tables in Databricks, so table-backed queries do not need to reference this database. When configuring a Databricks cluster, you can hide immuta from any calls to SHOW DATABASES so that users are not confused or misled by that database.
immuta DatabaseWhen configuring a Databricks cluster, hide immuta by using the following environment variable in the Spark cluster configuration:
Then, Immuta will not show this database when a SHOW DATABASES query is performed.
Immuta supports the use of external metastores in local or remote mode , following the same configuration detailed in the Databricks documentation.
Download the metastore jars and point to them as specified in Databricks documentation. Metastore jars must end up on the cluster's local disk at this explicit path: /databricks/hive_metastore_jars.
If using DBR 7.x with Hive 2.3.x, either
Set spark.sql.hive.metastore.version to 2.3.7 and spark.sql.hive.metastore.jars to builtin or
Download the metastore jars and set spark.sql.hive.metastore.jars to /databricks/hive_metastore_jars/* as before.
To use AWS Glue Data Catalog as the metastore for Databricks, see the Databricks documentation.
Cluster 1
9.1
Unavailable
Unavailable
Cluster 2
10.4
Unavailable
Unavailable
Cluster 3
11.3
Unavailable
Cluster 4
11.3
Cluster 5
11.3
/