Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
The warehouse you select when configuring the Snowflake integration uses compute resources to set up the integration, register data sources, orchestrate policies, and run jobs like sensitive data discovery. Snowflake credit charges are based on the size of and amount of time the warehouse is active, not the number of queries run.
This document prescribes how and when to adjust the size and scale of clusters for your warehouse to manage workloads so that you can use Snowflake compute resources the most cost effectively.
In general, increase the size of and number of clusters for the warehouse to handle heavy workloads and multiple queries. Workloads are typically lighter after data sources are onboarded and policies are established in Immuta, so compute resources can be reduced after those workloads complete.
The Snowflake integration uses warehouse compute resources to sync policies created in Immuta to the Snowflake objects registered as data sources and, if enabled, to run sensitive data discovery and schema monitoring. Follow the guidelines below to adjust the warehouse size and scale according to your needs.
Enable auto-suspend and auto-resume to optimize resource use in Snowflake. In the Snowflake UI, the lowest auto suspend time setting is 5 minutes. However, through SQL query, you can set auto_suspend to 61 seconds (since the minimum uptime for a warehouse is 60 seconds). For example,
Sensitive data discovery uses compute resources for each table registered if it is enabled. Consider disabling sensitive data discovery when registering data sources if you have an external catalog available or a tagging strategy in place.
Register data before creating global policies. By default, Immuta does not apply a subscription policy on registered data (unless an existing global policy applies to it), which allows Immuta to only pull metadata instead of also applying policies when data sources are created. Registering data before policies are created reduces the workload and the Snowflake compute resources needed.
Begin onboarding with a small dataset of tables, and then review and monitor query performance in the Snowflake Query Monitor. Adjust the virtual warehouse accordingly to handle heavier loads.
Schema monitoring uses the compute warehouse that was employed during the initial ingestion. If you expect a low number of new tables or minimal changes to the table structure, consider scaling down the warehouse size.
Resize the warehouse after after data sources are registered and policies are established. For example,
For more details and guidance about warehouse sizing, see the Snowflake Warehouse Considerations documentation.
Even after your integration is configured, data sources are registered, and policies are established, changes to those data sources or policies may initiate heavy workloads. Follow the guidelines below to adjust your warehouse size and scale according to your needs.
Review your Snowflake query history to identify query performance and bottlenecks.
Check how many credits queries have consumed:
After reviewing query performance and cost, implement strategies above to adjust your warehouse.
Immuta is compatible with Snowflake Secure Data Sharing. Using both Immuta and Snowflake, organizations can share the policy-protected data of their Snowflake database with other Snowflake accounts with Immuta policies enforced in real time. This integration gives data consumers a live connection to the data and relieves data providers of the legal and technical burden of creating static data copies that leave their Snowflake environment.
Requirements:
Snowflake Enterprise Edition or higher
Immuta's table grants feature
This method requires that the data consumer account is registered as an Immuta user with the Snowflake user name equal to the consuming account.
At that point, the user that represents the account being shared with can have the appropriate attributes and groups assigned to them, relevant to the data policies that need to be enforced. Once that user has access to the share in the consuming account (not managed by Immuta), they can query the share with the data policies from the producer account enforced because Immuta is treating that account as if they are a single user in Immuta.
For a tutorial on this workflow, see the Using Snowflake Data Sharing page.
Using Immuta with Snowflake Data Sharing allows the sharer to
Only need limited knowledge of the context or goals of the existing policies in place: Because the sharer is not editing or creating policies to share their data, they only need a limited knowledge of how the policies work. Their main responsibility is making sure they properly represent the attributes of the data consumer (the account being shared to).
Leave policies untouched.
Snowflake table grants simplifies the management of privileges in Snowflake when using Immuta. Instead of having to manually grant users access to tables registered in Immuta, you allow Immuta to manage privileges on your Snowflake tables and views according to subscription policies. Then, users subscribed to a data source in Immuta can view and query the Snowflake table, while users who are not subscribed to the data source cannot view or query the Snowflake table.
Enabling Snowflake table grants gives the following privileges to the Immuta Snowflake role:
MANAGE GRANTS ON ACCOUNT allows the Immuta Snowflake role to grant and revoke SELECT privileges on Snowflake tables and views that have been added as data sources in Immuta.
CREATE ROLE ON ACCOUNT allows for the creation of a Snowflake role for each user in Immuta, enabling fine-grained, attribute-based access controls to determine which tables are available to which individuals.
Since table privileges are granted to roles and not to users in Snowflake, Immuta's Snowflake table grants feature creates a new Snowflake role for each Immuta user. This design allows Immuta to manage table grants through fine-grained access controls that consider the individual attributes of users.
Each Snowflake user with an Immuta account will be granted a role that Immuta manages. The naming convention for this role is <IMMUTA>_USER_<username>, where
<IMMUTA> is the prefix you specified when enabling the feature on the Immuta app settings page.
<username> is the user's Immuta username.
Users are granted access to each Snowflake table or view automatically when they are subscribed to the corresponding data source in Immuta.
Users have two options for querying Snowflake tables that are managed by Immuta:
Use the role that Immuta creates and manages. (For example, USE ROLE IMMUTA_USER_<username>. See the section above for details about the role and name conventions.) If the current active primary role is used to query tables, USAGE on a Snowflake warehouse must be granted to the Immuta-managed Snowflake role for each user.
USE SECONDARY ROLES ALL, which allows users to use the privileges from all roles that they have been granted, including IMMUTA_USER_<username>, in addition to the current active primary role. Users may also set a value for DEFAULT_SECONDARY_ROLES as an object property on a Snowflake user. To learn more about primary roles and secondary roles in Snowflake, see Snowflake documentation.
Immuta uses an algorithm to determine the most optimal way to group users in a role hierarchy in order to optimize the number of GRANTs (or REVOKES) executed in Snowflake. This is done by determining the least amount of possible permutations of access across tables and users based on the policies in place; then, those become intermediate roles in the hierarchy that each user is added to, based on the intermediate roles they belong to.
As an example, take the below users and data sources they have access to. To do this naively by individually granting every user to the tables they have access to would result in 37 grants:
Conversely, using the Immuta algorithm, we can optimize the number of grants in the same scenario down to 29:
It’s important to consider a few things here:
If the permutations of access are small, there will be a huge optimization realized (very few intermediate roles). If every user has their own unique permutation of access, the optimization will be negligible (an intermediate role per user). It is most common that the number of permutations of access will be many multiples smaller than the actual user count, so there should be large optimizations. In other words, a much smaller number of intermediate roles and the number of total overall grants reduced, since the tables are granted to roles and roles to users.
This only happens once up front. After that, changes are incremental based on policy changes and user attribute changes (smaller updates), unless there’s a policy that makes a sweeping change across all users. The addition of new users who have access becomes much more straightforward also due to the fact above. User’s access will be granted via the intermediate role, and, therefore, a lot of the work is front loaded in the intermediate role creation.
Project workspaces are not supported when Snowflake table grants is enabled.
If an Immuta tenant is connected to an external IAM and that external IAM has a username identical to another username in Immuta's built-in IAM, those users will have the same Snowflake role, leading both to see the same data.
Sometimes the role generated can contain special characters such as @ because it's based on the user name configured from your identity manager. Because of this, it is recommended that any code references to the Immuta-generated role be enclosed with double quotes.
Snowflake Enterprise Edition required
In this integration, Immuta manages access to Snowflake tables by administering Snowflake row access policies and column masking policies on those tables, allowing users to query tables directly in Snowflake while dynamic policies are enforced.
Like with all Immuta integrations, Immuta can inject its ABAC model into policy building and administration to remove policy management burden and significantly reduce role explosion.
When an administrator configures the Snowflake integration with Immuta, Immuta creates an IMMUTA database and schemas (immuta_procedures, immuta_policies, and immuta_functions) within Snowflake to contain policy definitions and user entitlements. Immuta then creates a system role and gives that system account the following privileges:
APPLY MASKING POLICY
APPLY ROW ACCESS POLICY
ALL PRIVILEGES ON DATABASE "IMMUTA" WITH GRANT OPTION
ALL PRIVILEGES ON ALL SCHEMAS IN DATABASE "IMMUTA" WITH GRANT OPTION
USAGE ON FUTURE PROCEDURES IN SCHEMA "IMMUTA".immuta_procedures WITH GRANT OPTION
USAGE ON WAREHOUSE
OWNERSHIP ON SCHEMA "IMMUTA".immuta_policies TO ROLE "IMMUTA_SYSTEM" COPY CURRENT GRANTS
OWNERSHIP ON SCHEMA "IMMUTA".immuta_procedures TO ROLE "IMMUTA_SYSTEM" COPY CURRENT GRANTS
OWNERSHIP ON SCHEMA "IMMUTA".immuta_functions TO ROLE "IMMUTA_SYSTEM" COPY CURRENT GRANTS
OWNERSHIP ON SCHEMA "IMMUTA".public TO ROLE "IMMUTA_SYSTEM" COPY CURRENT GRANTS
Optional features, like automatic object tagging, native query auditing, etc., require additional permissions to be granted to the Immuta system account, are listed in the supported features section.
Snowflake is a policy push integration with Immuta. When Immuta users create policies, they are then pushed into the Immuta database within Snowflake; there, the Immuta system account applies Snowflake row access policies and column masking policies directly onto Snowflake tables. Changes in Immuta policies, user attributes, or data sources trigger webhooks that keep the Snowflake policies up-to-date.
For a user to query Immuta-protected data, they must meet two qualifications:
They must be subscribed to the Immuta data source.
They must be granted SELECT access on the table by the Snowflake object owner or automatically via the Snowflake table grants feature.
After a user has met these qualifications they can query Snowflake tables directly.
See the integration support matrix on the Data policy types reference guide for a list of supported data policy types in Snowflake.
When a user applies a masking policy to a Snowflake data source, Immuta truncates masked values to align with Snowflake column length (VARCHAR(X) types) and precision (NUMBER (X,Y) types) requirements.
Consider these columns in a data source that have the following masking policies applied:
Column A (VARCHAR(6)): Mask using hashing for everyone
Column B (VARCHAR(5)): Mask using a constant REDACTED for everyone
Column C (VARCHAR(6)): Mask by making null for everyone
Column D (NUMBER(3, 0)): Mask by rounding to the nearest 10 for everyone
Querying this data source in Snowflake would return the following values:
5w4502
REDAC
990
6e3611
REDAC
750
9s7934
REDAC
380
Hashing collisions
Hashing collisions are more likely to occur across or within Snowflake columns restricted to short lengths, since Immuta truncates the hashed value to the limit of the column. (Hashed values truncated to 5 characters have a higher risk of collision than hashed values truncated to 20 characters.) Therefore, avoid applying hashing policies to Snowflake columns with such restrictions.
For more details about Snowflake column length and precision requirements, see the Snowflake behavior change release documentation.
When a policy is applied to a column, Immuta uses Snowflake memoizable functions to cache the result of the called function. Then, when a user queries a column that has that policy applied to it, Immuta uses that cached result to dramatically improve query performance.
Register Snowflake data sources using a dedicated Snowflake role. Avoid using individual user accounts for data source onboarding. Instead, create a service account (Snowflake user account TYPE=SERVICE) with SELECT access for onboarding data sources. No policies will apply to that role, ensuring that your integration works with the following use cases:
Snowflake project workspaces: Snowflake workspaces generate static views with the credentials used to register the table as an Immuta data source. Those tables must be registered in Immuta by an excepted role so that policies applied to the backing tables are not applied to the project workspace views.
Using views and tables within Immuta: Because this integration uses Snowflake governance policies, users can register tables and views as Immuta data sources. However, if you want to register views and apply different policies to them than their backing tables, the owner of the view must be an excepted role; otherwise, the backing table’s policies will be applied to that view.
Private preview: This feature is only available to select accounts. Reach out to your Immuta representative to enable this feature.
Bulk data source creation is the more efficient process when loading more than 5000 data sources from Snowflake and allows for data sources to be registered in Immuta before running sensitive data discovery or applying policies.
To use this feature, see the Bulk create Snowflake data sources guide.
Based on performance tests that create 100,000 data sources, the following minimum resource allocations need to be applied to the appropriate pods in your Kubernetes environment for successful bulk data source creation.
Memory
4Gi
16Gi
CPU
2
4
Storage
8Gi
24Gi
Performance gains are limited when enabling sensitive data discovery at the time of data source creation.
External catalog integrations are not recognized during bulk data source creation. Users must manually trigger a catalog sync for tags to appear on the data source through the data source's health check.
Excepted roles and users are assigned when the integration is installed, and no policies will apply to these users' queries, despite any Immuta policies enforced on the tables they are querying. Credentials used to register a data source in Immuta will be automatically added to this excepted list for that Snowflake table. Consequently, roles and users added to this list and used to register data sources in Immuta should be limited to service accounts.
Immuta excludes the listed roles and users from policies by wrapping all policies in a CASE statement that will check if a user is acting under one of the listed usernames or roles. If a user is, then the policy will not be acted on the queried table. If the user is not, then the policy will be executed like normal. Immuta does not distinguish between role and username, so if you have a role and user with the exact same name, both the user and any user acting under that role will have full access to the data sources and no policies will be enforced for them.
An Immuta application administrator configures the Snowflake integration and registers Snowflake warehouse and databases with Immuta.
Immuta creates a database inside the configured Snowflake warehouse that contains Immuta policy definitions and user entitlements.
A data owner registers Snowflake tables in Immuta as data sources.
If Snowflake tag ingestion was enabled during the configuration, Immuta uses the host provided in the configuration and ingests internal tags on Snowflake tables registered as Immuta data sources.
A data owner, data governor, or administrator creates or changes a policy or a user's attributes change in Immuta.
The Immuta web service calls a stored procedure that modifies the user entitlements or policies.
Immuta manages and applies Snowflake governance column and row access policies to Snowflake tables that are registered as Immuta data sources.
If Snowflake table grants is not enabled, Snowflake object owner or user with the global MANAGE GRANTS privilege grants SELECT privilege on relevant Snowflake tables to users. Note: Although they are GRANTed access, if they are not subscribed to the table via Immuta-authored policies, they will not see data.
A Snowflake user who is subscribed to the data source in Immuta queries the corresponding table directly in Snowflake and sees policy-enforced data.
The Snowflake integration supports the following authentication methods to configure the integration and create data sources:
Username and password: Users can authenticate with their Snowflake username and password.
Key pair: Users can authenticate with a Snowflake key pair authentication.
Snowflake External OAuth: Users can authenticate with Snowflake External OAuth.
Immuta's OAuth authentication method uses the Client Credentials Flow to integrate with Snowflake External OAuth. When a user configures the Snowflake integration or connects a Snowflake data source, Immuta uses the token credentials (obtained using a certificate or passing a client secret) to craft an authenticated access token to connect with Snowflake. This allows organizations that already use Snowflake External OAuth to use that secure authentication with Immuta.
An Immuta application administrator configures the Snowflake integration or creates a data source.
Immuta creates a custom token and sends it to the authorization server.
The authorization server confirms the information sent from Immuta and issues an access token to Immuta.
Immuta sends the access token it received from the authorization server to Snowflake.
Snowflake authenticates the token and grants access to the requested resources from Immuta.
The integration is connected and users can query data.
The Immuta Snowflake integration supports Snowflake external tables. However, you cannot add a masking policy to an external table column while creating the external table in Snowflake because masking policies cannot be attached to virtual columns.
The Snowflake integration supports the Immuta features outlined below. Click the links provided for more details.
Immuta project workspaces: Users can have additional write access in their integration using project workspaces.
Tag ingestion: Immuta automatically ingests Snowflake object tags from your Snowflake instance and adds them to the appropriate data sources.
User impersonation: Native impersonation allows users to natively query data as another Immuta user. To enable native user impersonation, see the Integration user impersonation page.
Native query audit: Immuta audits queries run natively in Snowflake against Snowflake data registered as Immuta data sources.
Snowflake low row access policy mode: The Snowflake low row access policy mode improves query performance in Immuta's Snowflake integration by decreasing the number of Snowflake row access policies Immuta creates.
Snowflake table grants: This feature allows Immuta to manage privileges on your Snowflake tables and views according to the subscription policies on the corresponding Immuta data sources.
Immuta system account required Snowflake privileges
CREATE [OR REPLACE] PROCEDURE
DROP ROLE
REVOKE ROLE
Users can have additional write access in their integration using project workspaces. For more details, see the Snowflake project workspaces page.
To use project workspaces with the Snowflake integration, the default role of the account used to create data sources in the project must be added to the "Excepted Roles/Users List." If the role is not added, you will not be able to query the equalized view using the project role in Snowflake.
You can enable Snowflake tag ingestion so that Immuta will ingest Snowflake object tags from your Snowflake instance into Immuta and add them to the appropriate data sources.
The Snowflake tags' key and value pairs will be reflected in Immuta as two levels: the key will be the top level and the value the second. As Snowflake tags are hierarchical, Snowflake tags applied to a database will also be applied to all of the schemas in that database, all of the tables within those schemas, and all of the columns within those tables. For example: If a database is tagged PII, all of the tables and columns in that database will also be tagged PII.
To enable Snowflake tag ingestion, see the Configure a Snowflake integration page.
Snowflake has some natural data latency. If you manually refresh the governance page to see all tags created globally, users can experience a delay of up to two hours. However, if you run schema detection or a health check to find where those tags are applied, the delay will not occur because Immuta will only refresh tags for those specific tables.
Immuta system account required Snowflake privilege
IMPORTED PRIVILEGES ON DATABASE snowflake
Once this feature has been enabled with the Snowflake integration, Immuta will query Snowflake to retrieve user query histories. These histories provide audit records for queries against Snowflake data sources that are queried natively in Snowflake.
This process will happen automatically every hour by default but can be configured to a different frequency when configuring or editing the integration. Additionally, audit ingestion can be manually requested at any time from the Immuta audit page. When manually requested, it will only search for new queries that were created since the last native query that had been audited. The job is run in the background, so the new queries will not be immediately available.
For details about prompting these logs and the contents of these audit logs, see the Snowflake query audit logs page.
A user can configure multiple integrations of Snowflake to a single Immuta tenant and use them dynamically or with workspaces.
There can only be one integration connection with Immuta per host.
The host of the data source must match the host of the integration for the view to be created.
Projects can only be configured to use one Snowflake host.
If there are errors in generating or applying policies natively in Snowflake, the data source will be locked and only users on the excepted roles/users list and the credentials used to create the data source will be able to access the data.
Once a Snowflake integration is disabled in Immuta, the user must remove the access that was granted in Snowflake. If that access is not revoked, users will be able to access the raw table in Snowflake.
Migration must be done using the credentials and credential method (automatic or bootstrap) used to configure the integration.
When configuring one Snowflake instance with multiple Immuta tenants, the user or system account that enables the integration on the app settings page must be unique for each Immuta tenant.
A Snowflake table can only have one set of policies enforced at a given time, so creating multiple data sources pointing to the same table is not supported. If this is a use case you need to support, create views in Snowflake and expose those instead.
You cannot add a masking policy to an external table column while creating the external table because a masking policy cannot be attached to a virtual column.
If you create an Immuta data source from a Snowflake view created using a select * from query, Immuta column detection will not work as expected because Snowflake views are not automatically updated based on backing table changes. To remedy this, you can create views that have the specific columns you want or you can CREATE AND REPLACE the view in Snowflake whenever the backing table is updated and manually run the column detection job on the data source page.
If a user is created in Snowflake after that user is already registered in Immuta, Immuta does not grant usage on the per-user role automatically - meaning Immuta does not govern this user's access without manual intervention. If a Snowflake user is created after that user is registered in Immuta, the user account must be disabled and re-enabled to trigger a sync of Immuta policies to govern that user. Whenever possible, Snowflake users should be created before registering those users in Immuta.
Snowflake tables from imported databases are not supported. Instead, create a view of the table and register that view as a data source.
The Immuta Snowflake integration uses Snowflake governance features to let users query data natively in Snowflake. This means that Immuta also inherits some Snowflake limitations using correlated subqueries with row access policies and column-level security. These limitations appear when writing custom WHERE policies, but do not remove the utility of row-level policies.
All column names must be fully qualified: Any column names that are unqualified (i.e., just the column name) will default to a column of the data source the policy is being applied to (if one matches the name).
The Immuta system account must have SELECT privileges on all tables/views referenced in a subquery: The Immuta system role name is specified by the user, and the role is created when the Snowflake instance is integrated.
Any subqueries that error in Snowflake will also error in Immuta.
Including one or more subqueries in the Immuta policy condition may cause errors in Snowflake. If an error occurs, it may happen during policy creation or at query-time. To avoid these errors, limit the number of subqueries, limit the number of JOIN operations, and simplify WHERE clause conditions.
For more information on the Snowflake subquery limitations see
Private preview: This feature is only available to select accounts. Reach out to your Immuta representative to enable this feature.
Snowflake column lineage specifies how data flows from source tables or columns to the target tables in write operations. When Snowflake lineage tag propagation is enabled in Immuta, Immuta automatically applies tags added to a Snowflake table to its descendant data source columns in Immuta so you can build policies using those tags to restrict access to sensitive data.
Snowflake Access History tracks user read and write operations. Snowflake column lineage extends this Access History to specify how data flows from source columns to the target columns in write operations, allowing data stewards to understand how sensitive data moves from ancestor tables to target tables so that they can
trace data back to its source to validate the integrity of dashboards and reports,
identify who performed write operations to meet compliance requirements,
evaluate data quality and pinpoint points of failure, and
tag sensitive data on source tables without having tag columns on their descendant tables.
However, tagging sensitive data doesn’t innately protect that data in Snowflake; users need Immuta to disseminate these lineage tags automatically to descendant tables registered in Immuta so data stewards can build policies using the semantic and business context captured by those tags to restrict access to sensitive data. When Snowflake lineage tag propagation is enabled, Immuta propagates tags applied to a data source to its descendant data source columns in Immuta, which keeps your data inventory in Immuta up-to-date and allows you to protect your data with policies without having to manually tag every new Snowflake data source you register in Immuta.
An application administrator enables the feature on the Immuta app settings page.
Snowflake lineage metadata (column names and tags) for the Snowflake tables is stored in the metadata database.
A data owner creates a new data source (or adds a new column to a Snowflake table) that initiates a job that applies all tags for each column from its ancestor columns.
A data owner or governor adds a tag to a column in Immuta that has descendants, which initiates a job that propagates the tag to all descendants.
An audit record is created that includes which tags were applied and from which columns those tags originated.
The Snowflake Account Usage ACCESS_HISTORY view contains column lineage information.
To appropriately propagate tags to descendant data sources, Immuta fetches Access History metadata to determine what column tags have been updated, stores this metadata in the Immuta metadata database, and then applies those tags to relevant descendant columns of tables registered in Immuta.
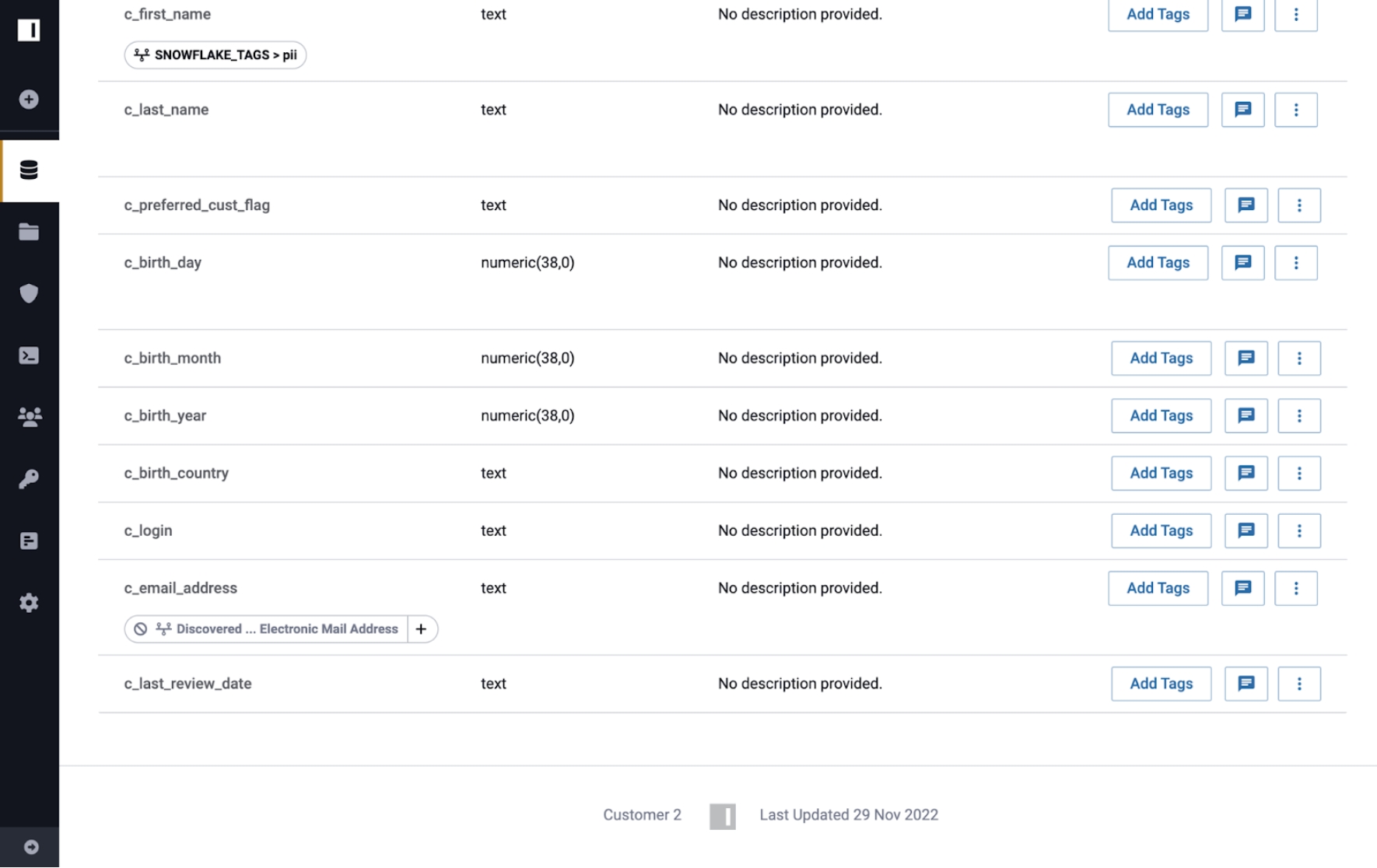
Consider the following example using the Customer, Customer 2, and Customer 3 tables that were all registered in Immuta as data sources.
Customer: source table
Customer 2: descendant of Customer
Customer 3: descendant of Customer 2
If the Discovered.Electronic Mail Address tag is added to the Customer data source in Immuta, that tag will propagate through lineage to the Customer 2 and Customer 3 data sources.
After an application administrator has enabled Snowflake lineage tag propagation, data owners can register data in Immuta and have tags in Snowflake propagated from ancestor tables to descendant data sources. Whenever new tags are added to those tables in Immuta, those upstream tags will propagate to descendant data sources.
By default all tags are propagated, but these tags can be filtered on the app settings page or using the Immuta API.
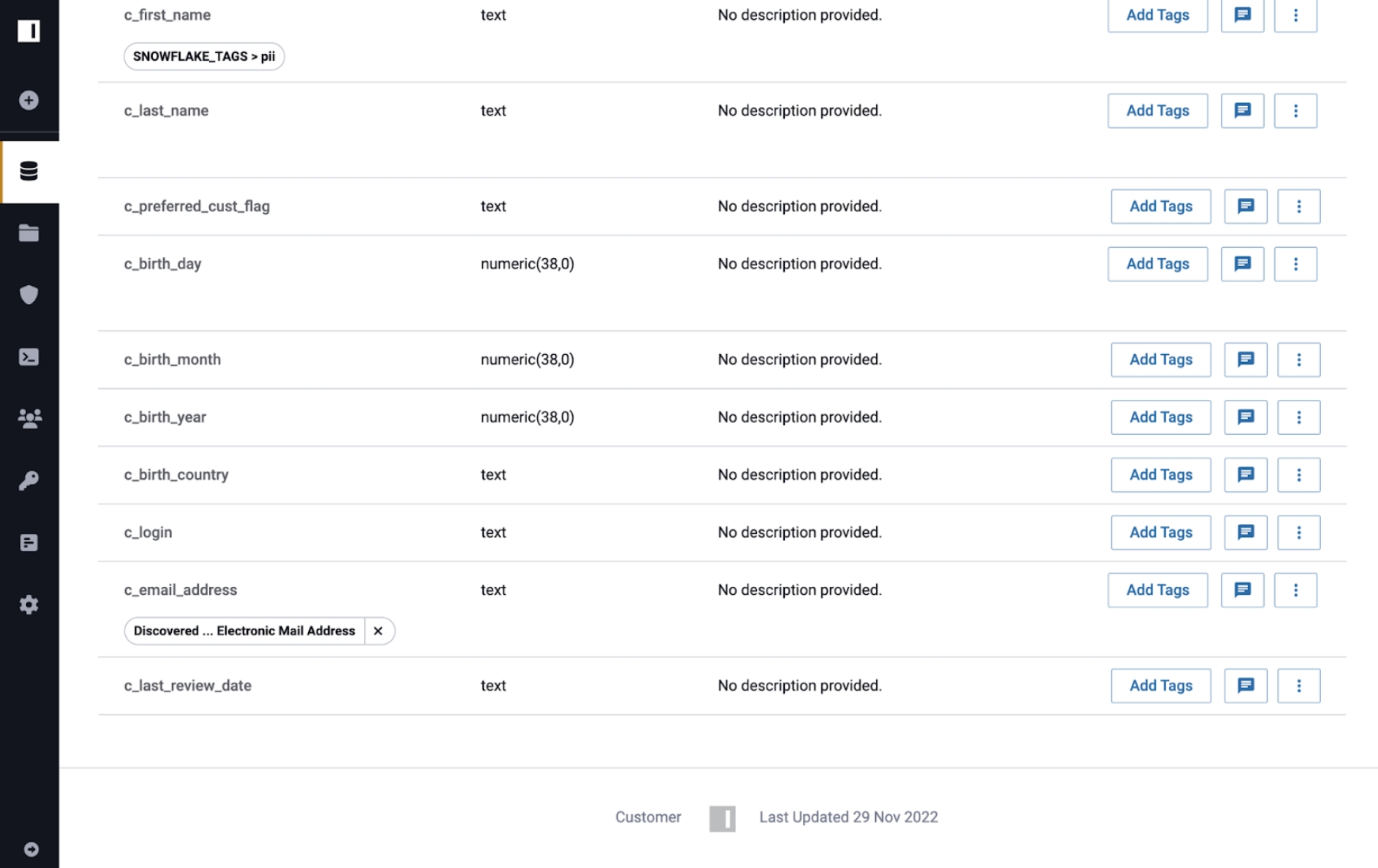
Lineage tag propagation works with any tag added to the data dictionary. Tags can be manually added, synced from an external catalog, or discovered by SDD. Consider the following example using the Customer, Customer 2, and Customer 3 tables that were all registered in Immuta as data sources.
Customer: source table
Customer 2: descendant of Customer
Customer 3: descendant of Customer 2
Immuta added the Discovered.Electronic Mail Address tag to the Customer data source, and that tag propagated through lineage to the Customer 2 and Customer 3 data sources.
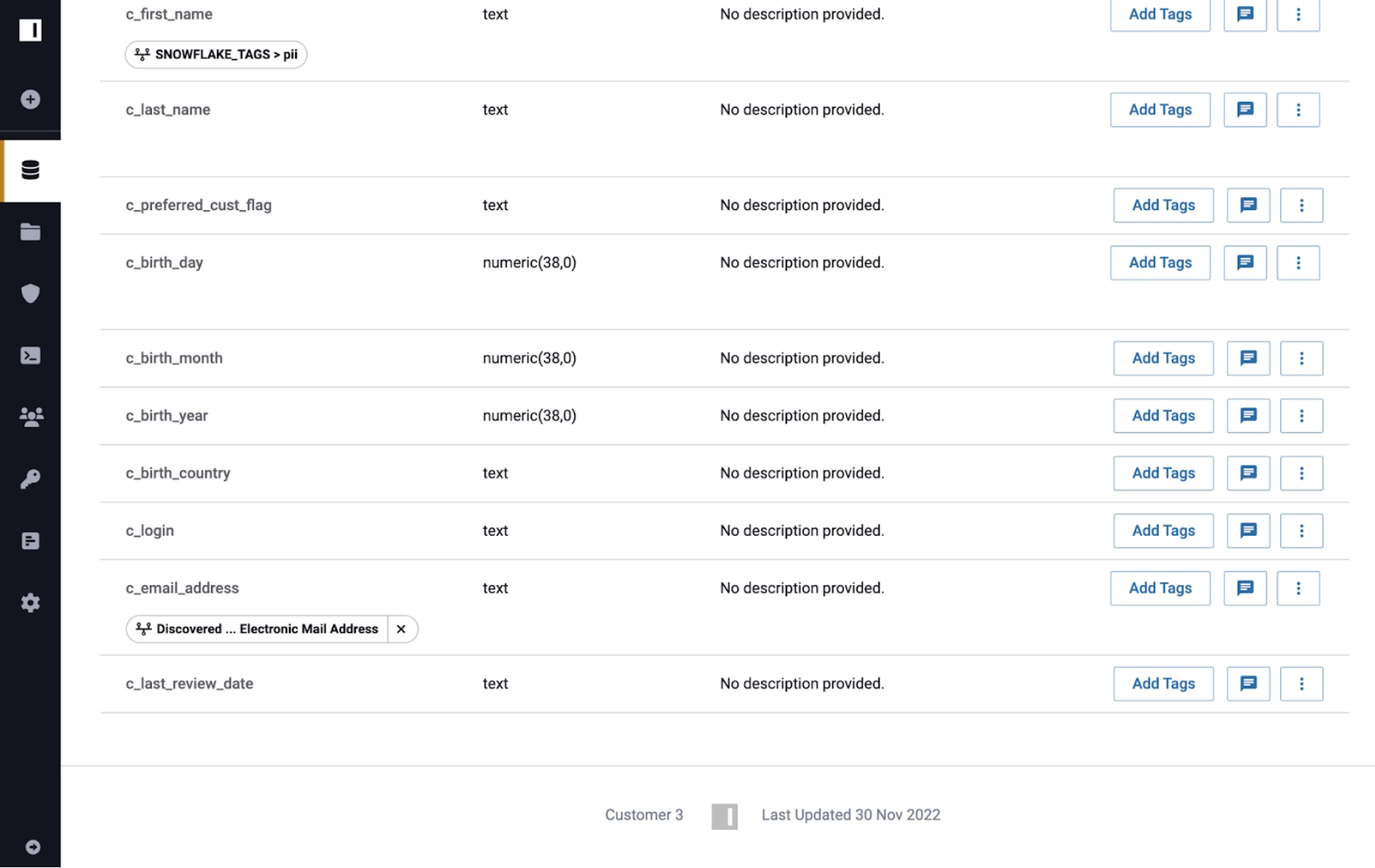
Removing the tag from the Customer 2 table soft deletes it from the Customer 2 data source. When a tag is deleted, downstream lineage tags are removed, unless another parent data source still has that tag. The tag remains visible, but it will not be re-added if a future propagation event specifies the same tag again. Immuta prevents you from removing Snowflake object tags from data sources. You can only remove Immuta-managed tags. To remove Snowflake object tags from tables, you must remove them in Snowflake.
However the Discovered.Electronic Mail Address tag still applies to the Customer 3 data source because Customer still has the tag applied. The only way a tag will be removed from descendant data sources is if no other ancestor of the descendant still prescribes the tag.
If the Snowflake lineage tag propagation feature is disabled, tags will remain on Immuta data sources.
Immuta audit records include Snowflake lineage tag events when a tag is added or removed.
The example audit record below illustrates the SNOWFLAKE_TAGS.pii tag successfully propagating from the Customer table to Customer 2:
Without tableFilter set, Immuta will ingest lineage for every table on the Snowflake instance.
Tag propagation based on lineage is not retroactive. For example, if you add a table, add tags to that table, and then run the lineage ingestion job, tags will not get propagated. However, if you add a table, run the lineage ingestion job, and then add tags to the table, the tags will get propagated.
The native lineage job needs to pull in lineage data before any tag is applied in Immuta. When Immuta gets new lineage information from Snowflake, Immuta does not update existing tags in Immuta.
There can be up to a 3-hour delay in Snowflake for a lineage event to make it into the ACCESS_HISTORY view.
Immuta does not ingest lineage information for views.
Snowflake only captures lineage events for CTAS, CLONE, MERGE, and INSERT write operations. Snowflake does not capture lineage events for DROP, RENAME, ADD, or SWAP. Instead of using these latter operations, you need to recreate a table with the same name if you need to make changes.
Immuta cannot enforce coherence of your Snowflake lineage. If a column, table, or schema in the middle of the lineage graph gets dropped, Immuta will not do anything unless a table with that same name gets recreated. This means a table that gets dropped but not recreated could live in Immuta’s system indefinitely.
The Snowflake low row access policy mode improves query performance in Immuta's Snowflake integration by decreasing the number of Immuta creates and by using table grants to manage user access.
Immuta manages access to Snowflake tables by administering and on those tables, allowing users to query them directly in Snowflake while policies are enforced.
Without Snowflake low row access policy mode enabled, row access policies are created and administered by Immuta in the following scenarios:
are disabled and a subscription policy that does not automatically subscribe everyone to the data source is applied. Immuta administers Snowflake row access policies to filter out all the rows to restrict access to the entire table when the user doesn't have privileges to query it. However, if table grants are disabled and a subscription policy is applied that grants everyone access to the data source automatically, Immuta does not create a row access policy in Snowflake. See the for details about these policy types.
is applied to a data source. A row access policy filters out all the rows of the table if users aren't acting under the purpose specified in the policy when they query the table.
is applied to a data source. A row access policy filters out rows querying users don't have access to.
is enabled. A row access policy is created for every Snowflake table registered in Immuta.
Deprecation notice
Support for using the Snowflake integration with low row access policy mode disabled has been deprecated. You must enable this feature and table grants for your integration to continue working in future releases. See the for EOL dates.
Snowflake low row access policy mode is enabled by default to reduce the number of row access policies Immuta creates and improve query performance. Snowflake low row access policy mode requires
.
user impersonation to be disabled. User impersonation diminishes the performance of interactive queries because of the number of row access policies Immuta creates when it's enabled.
Project workspaces are not compatible with this feature.
Impersonation is not supported when the Snowflake low row access policy mode is enabled.
will still run on data sources and can be manually triggered. Tags applied through sensitive data discovery will propagate as tags added through lineage to descendant Immuta data sources.
Project-scoped purpose exceptions for Snowflake integrations allow you to apply to Snowflake data sources in a project. As a result, users can only access that data when they are working within that specific project.
This feature allows masked columns to be joined across data sources that belong to the same project. When data sources do not belong to a project, Immuta uses a unique salt per data source for hashing to prevent masked values from being joined. (See the guide for an explanation of that behavior.) However, once you add Snowflake data sources to a project and enable masked joins, Immuta uses a consistent salt across all the data sources in that project to allow the join.
For more information about masked joins and enabling them for your project, see the of documentation.