Databricks SQL Integration Overview (Public Preview)
Audience: System Administrators, Data Governors, and Data Owners
Content Summary: This page provides an overview of the Databricks SQL integration in Immuta. For a tutorial detailing how to enable this integration, see the installation guide. Databricks SQL is currently in Public Preview. Please provide feedback on any issues you encounter, as well as insight regarding how you would like this feature to evolve in the future.
Overview
Immuta’s Databricks SQL integration provides users direct access to views in a protected database Immuta creates inside Databricks SQL when the integration is configured. This protected database includes
- several tables and views Immuta creates to enable policy enforcement (storage of user entitlements, UDFs, etc.).
- views that contain policy logic corresponding to the target data source exposed in Immuta by a Data Owner. This view is exposed to all users in Databricks SQL.
Architecture
When an administrator configures the Databricks SQL integration with Immuta, Immuta creates
an immuta database and Databricks SQL creates a default database in the SQL Endpoint. Data sources
registered in Immuta are added as tables to the default database, and a view is created in the
immuta database for each of these tables.
The credentials provided to set up the integration must have the ability to
- create an integration database
- configure procedures and functions
- maintain state between Databricks and Immuta
De-Conflicting Tables
Databricks SQL has a two-level structure with databases and tables. To de-conflict these table names when Immuta
creates views in the Immuta-protected database, Immuta prepends each table name with its parent database
in Databricks SQL (which is configured in the Immuta UI). The following example illustrates a scenario
where multiple Databricks SQL databases are configured in Immuta
(whose protected database is named immuta_databricks_sql in the SQL Endpoint):
Datasource A:
- parent Databricks SQL database: public
- table name: HR_data
Datasource B:
- parent Databricks SQL database: default
- table name: HR_data
Resulting Immuta views created:
- Data Source A: immuta_databricks_sql.public_HR_data
- Data Source B: immuta_databricks_sql.default_HR_data
Policy Enforcement
Immuta uses dynamic views to enforce row- and column-level security in Databricks SQL. These dynamic views allow Immuta to manage which users have access to a view’s rows, columns, or specific records by filtering or masking their values.
When a Data Owner exposes a Databricks SQL table as a data source in Immuta and applies a policy to it,
Immuta updates the policy definition in the protected immuta database in Databricks SQL. Then, Immuta creates a dynamic
view based on the table in the default database, the querying users' entitlements, and policies that apply
to that table. Finally, Databricks SQL users query the view through the protected immuta database.
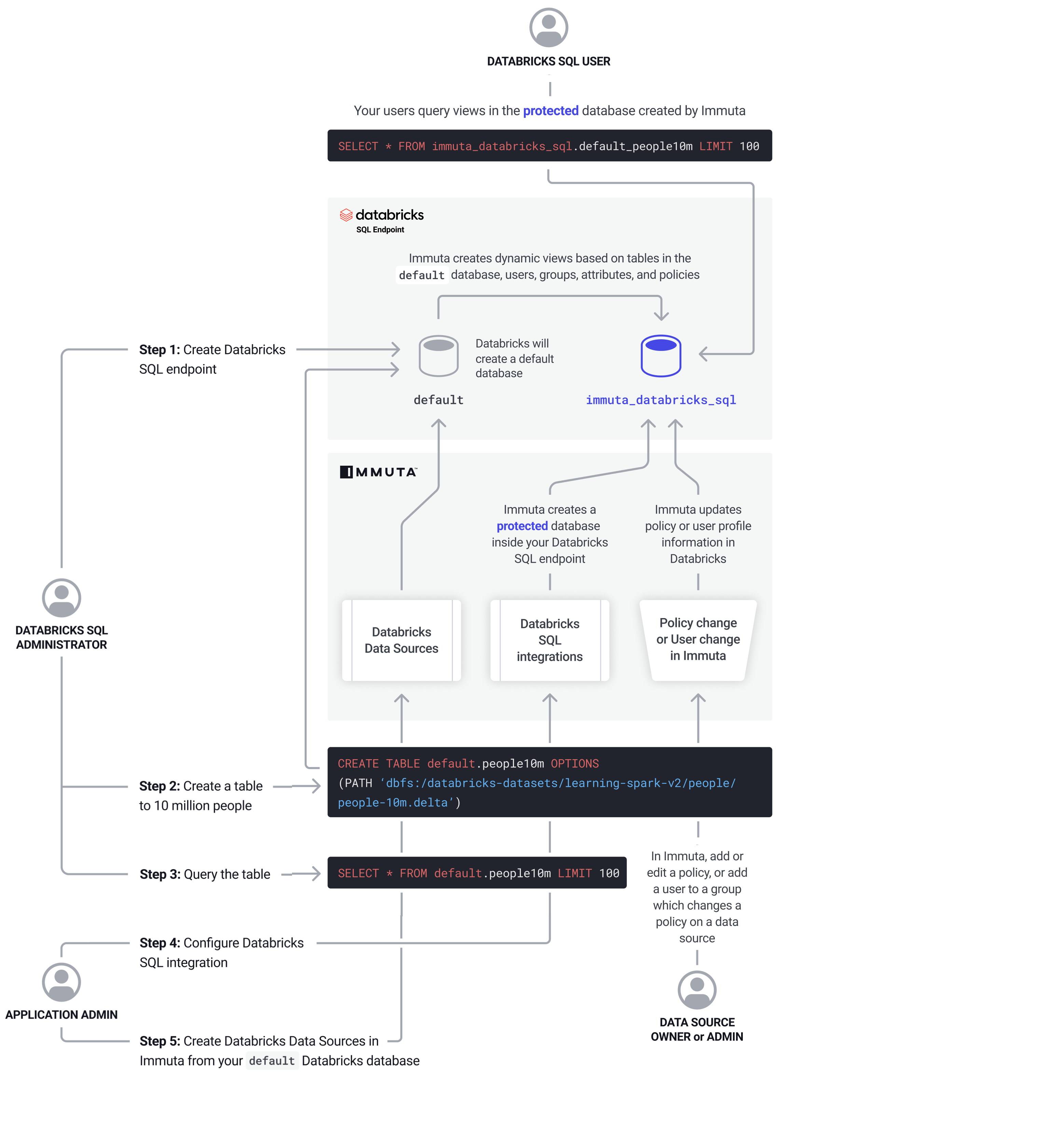
Data Flow
- A Databricks SQL Administrator creates a Databricks SQL endpoint.
- Databricks creates a
defaultdatabase. Note: Immuta doesn’t lock down access to the default database; an administrator must do that within Databricks SQL itself. - The Databricks Admin creates a table of 10 million people and queries the table.
- An Immuta Application Admin configures the Databricks SQL integration
- Immuta creates a protected database inside the Databricks SQL endpoint.
- A Data Owner
creates data sources
in Immuta from the
defaultDatabricks database. - A user adds or edits a policy, or adds a user to a group that changes a policy on a data source.
- Immuta updates the policy or user profile information in Databricks.
- Immuta creates dynamic views based on tables in the
defaultdatabase, users, groups, attributes, and policies. - Users query views in the protected database created by Immuta.