Snowflake Table Grants
Last updated
Was this helpful?


Last updated
Was this helpful?
Snowflake table grants simplifies the management of privileges in Snowflake when using Immuta. Instead of having to manually grant users access to tables registered in Immuta, you allow Immuta to manage privileges on your Snowflake tables and views according to subscription policies. Then, users subscribed to a data source in Immuta can view and query the Snowflake table, while users who are not subscribed to the data source cannot view or query the Snowflake table.
Enabling Snowflake table grants gives the following privileges to the Immuta Snowflake role:
MANAGE GRANTS ON ACCOUNT allows the Immuta Snowflake role to grant and revoke SELECT privileges on Snowflake tables and views that have been added as data sources in Immuta.
CREATE ROLE ON ACCOUNT allows for the creation of a Snowflake role for each user in Immuta, enabling fine-grained, attribute-based access controls to determine which tables are available to which individuals.
Since table privileges are granted to roles and not to users in Snowflake, Immuta's Snowflake table grants feature creates a new Snowflake role for each Immuta user. This design allows Immuta to manage table grants through fine-grained access controls that consider the individual attributes of users.
Each Snowflake user with an Immuta account will be granted a role that Immuta manages. The naming convention for this role is <IMMUTA>_USER_<username>, where
<IMMUTA> is the prefix you specified when enabling the feature on the Immuta app settings page.
<username> is the user's Immuta username.
Users are granted access to each Snowflake table or view automatically when they are subscribed to the corresponding data source in Immuta.
Users have two options for querying Snowflake tables that are managed by Immuta:
that Immuta creates and manages. (For example, USE ROLE IMMUTA_USER_<username>. See the for details about the role and name conventions.) If the current active primary role is used to query tables, USAGE on a Snowflake warehouse must be granted to the Immuta-managed Snowflake role for each user.
, which allows users to use the privileges from all roles that they have been granted, including IMMUTA_USER_<username>, in addition to the current active primary role. Users may also set a value for DEFAULT_SECONDARY_ROLES as an on a Snowflake user. To learn more about primary roles and secondary roles in Snowflake, see .
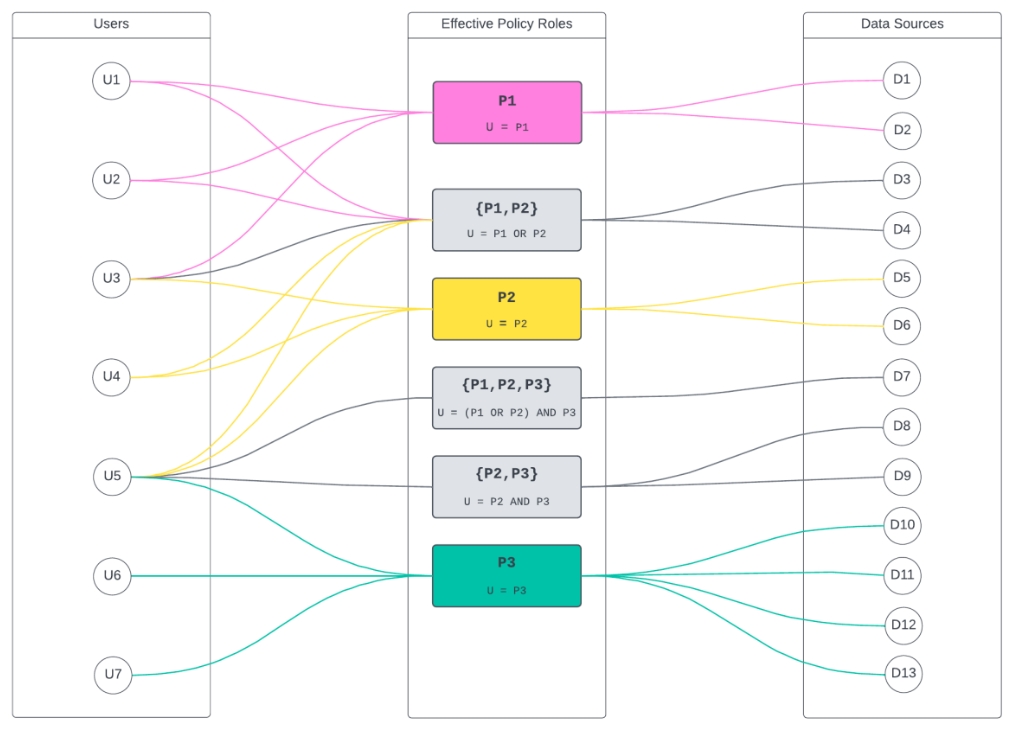
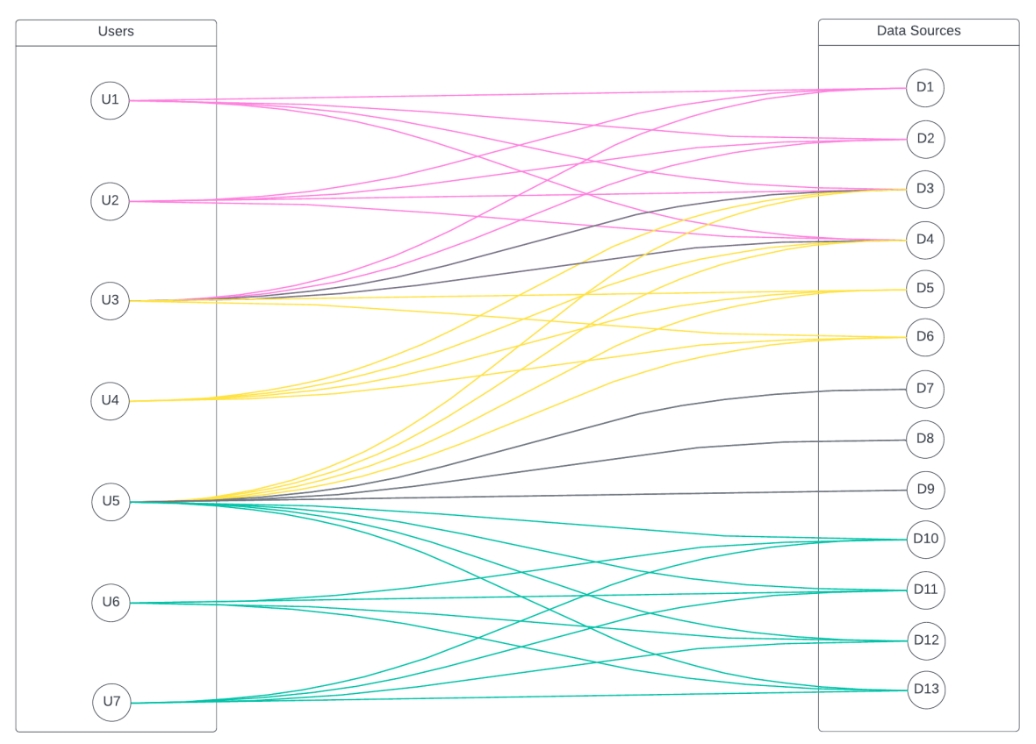
Immuta uses an algorithm to determine the most optimal way to group users in a role hierarchy in order to optimize the number of GRANTs (or REVOKES) executed in Snowflake. This is done by determining the least amount of possible permutations of access across tables and users based on the policies in place; then, those become intermediate roles in the hierarchy that each user is added to, based on the intermediate roles they belong to.
As an example, take the below users and data sources they have access to. To do this naively by individually granting every user to the tables they have access to would result in 37 grants:
Conversely, using the Immuta algorithm, we can optimize the number of grants in the same scenario down to 29:
It’s important to consider a few things here:
If the permutations of access are small, there will be a huge optimization realized (very few intermediate roles). If every user has their own unique permutation of access, the optimization will be negligible (an intermediate role per user). It is most common that the number of permutations of access will be many multiples smaller than the actual user count, so there should be large optimizations. In other words, a much smaller number of intermediate roles and the number of total overall grants reduced, since the tables are granted to roles and roles to users.
This only happens once up front. After that, changes are incremental based on policy changes and user attribute changes (smaller updates), unless there’s a policy that makes a sweeping change across all users. The addition of new users who have access becomes much more straightforward also due to the fact above. User’s access will be granted via the intermediate role, and, therefore, a lot of the work is front loaded in the intermediate role creation.
If an Immuta tenant is connected to an external IAM and that external IAM has a username identical to another username in Immuta's built-in IAM, those users will have the same Snowflake role, leading both to see the same data.
Sometimes the role generated can contain special characters such as @ because it's based on the user name configured from your identity manager. Because of this, it is recommended that any code references to the Immuta-generated role be enclosed with double quotes.
are not supported when Snowflake table grants is enabled.