

Custom REST Catalog Interface Endpoints
Architectural Overview
The diagram below contrasts Immuta's provided catalog integration architecture with this custom REST Catalog interface - which gives the user tremendous control over the metadata being provided to Immuta.
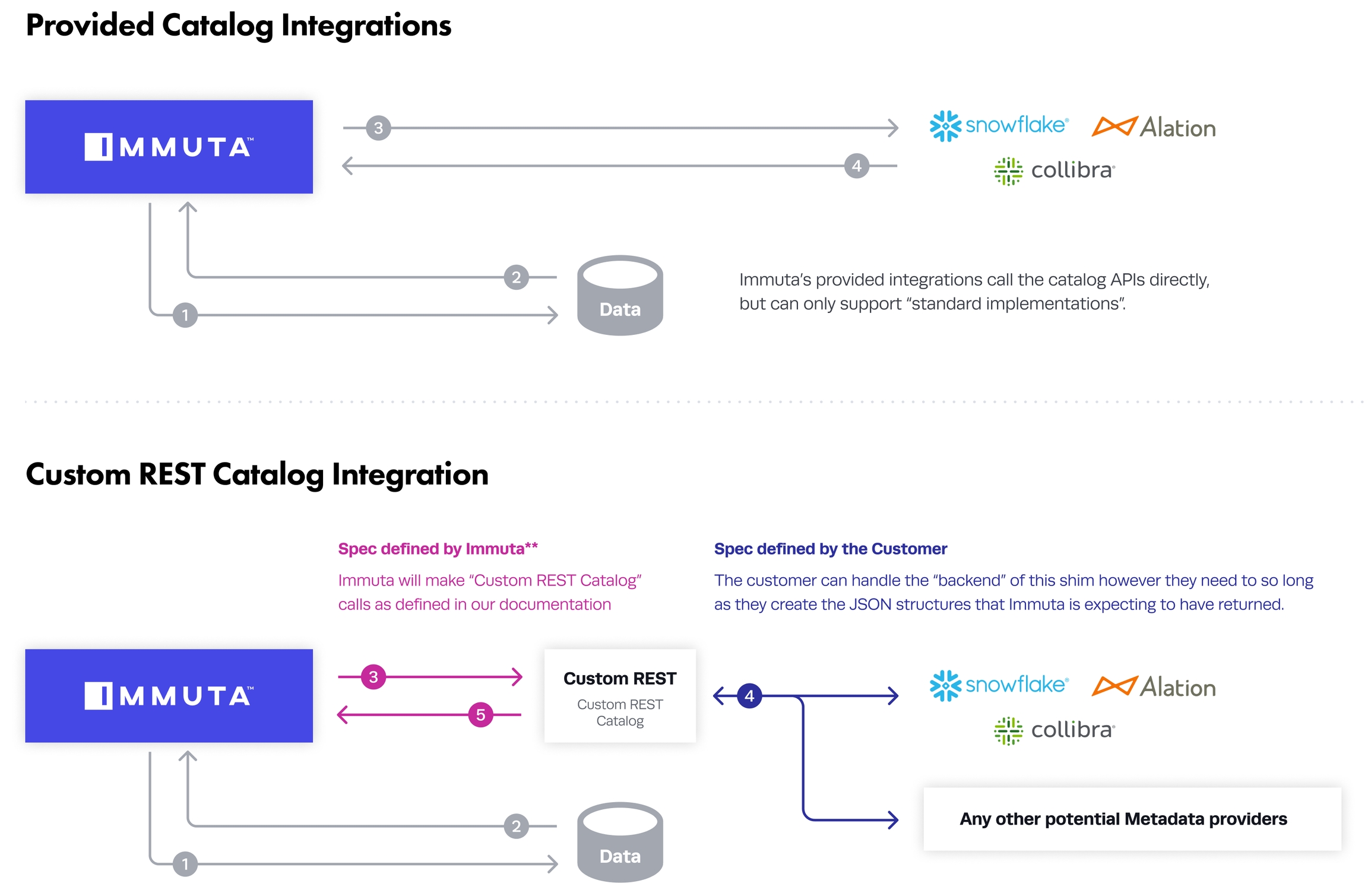
The custom-developed service must be built to receive and handle calls to the REST endpoints specified below. Immuta will call these endpoints as detailed below when certain events occur and at various intervals. The required responses to complete the connection are also detailed.
General Concepts
Tags in Immuta
Tags are attributes applied to data - either at the top, data source, level or at the individual column level.
Tags in Immuta take the form of a nested tree structure. There are "parents", "children", "grand-children", etc.:
| Parent (root)
|\_ Child1
| \_ Grandchild1 (leaf)
\_ Child2
\_ Grandchild1 (leaf)The REST Catalog interface interprets a tag's relationship mapping from a string based on a standard "dot" (.) notation, like:
"Parent.Child1.Grandchild1"Tags returned must meet the following constraints:
They must be no longer than 500 characters. Longer tags will not throw an error but will be truncated silently at 500 characters.
They must be composed of letters, digits, underscores, dashes, and whitespace characters. A period (
.) is used as a separator as described above. Other special characters are not supported.
A tag object has a single id property, which is used to uniquely identify the tag within the catalog. This id may be of either a string or integer type, and its value is completely up to the designer of the REST Catalog service. Common examples include: a standard integer value, a UUID, or perhaps a hash of the tag's string value (if it is unique within the system).
For this example REST Catalog interface, tags are represented in JSON like:
"<string>[.<string>[.<string>...]]": {
"id": "<unique identifier, string or int>"
},For example, the object below specifies 3 different tags:
"REST_Catalog_Root": {
"id": "id_is_set_by_catalog_and_can_be_int_or_string"
},
"REST_Catalog_Root.Child1": {
"id": "d3e859da-40e9-43d2-a302-294458e79a64"
},
"REST_Catalog_Root.Child2.Grandchild1": {
"id": 10
}For more information on tags and how they are created, managed, and displayed within Immuta, see our tag documentation.
Descriptions in Immuta
Descriptions are strings that, like tags, can be applied to either a data source or an individual column. These strings support UTF-8, including special and various language characters.
Authentication
Immuta can make requests to your REST Catalog service using any of the following authentication methods:
Username and password: Immuta can send requests with a username and a password in the Authorization HTTP header. In this case, the custom REST service will need to be able to parse a Basic Authorization Header and validate the credentials sent with it.
PKI Certificate: Immuta can also send requests using a CA certificate, a certificate, and a key.
NO Authentication: Immuta can make unauthenticated requests to your REST Catalog service. However, this should only be used if you have other security measures in place (e.g., if the service is in an isolated network that's reachable only by your Immuta environment).
Endpoint Specification
GET /tags
/tagsOverview
The /tags endpoint is used to collect ALL the tags the catalog can provide. It is used by Immuta to populate Immuta's tags list in the Governance section. These tags can then be used for policy creation ahead of actual data sources being created that make use of them. This enables policies to immediately apply when data sources are registered with Immuta.
As with all external catalogs, tags ingested by Immuta from the REST catalog interface are not able to be modified locally within Immuta as this catalog becomes the "source of truth" for them. This results in the tags showing in Immuta with either a lock icon next to them, or without the delete button that would allow a user to manually remove them from an assigned data source or column.
Request
The /tags endpoint receives a simple GET request from Immuta. No payload nor query parameters are required.
Example request:
curl http://<your_custom_rest_catalog>/tags \
--header 'Authorization: Basic <base64 of username:password>'Response
The Custom REST service must respond with an object that maps all tag name strings to associated ids. The tag name string fully-qualifies the location of the tag in the tree structure as detailed previously, and the id is a globally unique identifier assigned by the REST catalog to that tag.
The JSON format for this response object is:
{
"Parent": {"id": <tag_id1>},
"Parent.Child1": {"id": <tag_id2>},
"Parent.Child1.Grandchild1": {"id": <tag_id3>},
}Example response:
{
"REST_Catalog_Root": {
"id": "id_is_set_by_catalog_and_can_be_int_or_string"
},
"REST_Catalog_Root.Child1": {
"id": "d3e859da-40e9-43d2-a302-294458e79a64"
},
"REST_Catalog_Root.Child2.Grandchild1": {
"id": 10
}
}POST /dataSource
/dataSourceOverview
The /dataSource endpoint does the vast majority of the work. It receives a POST request from Immuta, and returns the mapping of a data source and its columns to the applied tags and descriptions.
Immuta will try to fetch metadata for a data source in the system at various times:
During data source creation. During data source creation, Immuta will send metadata to the REST Catalog service, most notably the connection details of the data source, which includes the schema and table name. It is important that the Custom REST service implemented can parse this information and search its records for an appropriate record to return with an ID unique to this data source in its
catalogMetadataobject.When a user manually links the data source. Data sources that either fail to auto-link, or that were created prior to the Custom REST catalog being configured, can still be manually linked. To do so, a data source owner can provide the ID of the asset as defined by the Custom REST Catalog via the Immuta UI. In order for this to work, the Custom REST Catalog service must support matching data source assets by unique ID.


During various refreshes. Once linked, Immuta will periodically call the
/dataSourceendpoint to ensure information is up to date.
Request
Immuta's POST requests to the /dataSource endpoint will consist of a payload containing many of the elements outlined below:
catalogMetadata
dictionary
Object holding the data source's catalog metadata.
catalogMetadata.id
string or integer
The unique identifier of the data source in the catalog.
catalogMetadata.name
string
The name of the data source in the catalog.
handlerInfo
dictionary
Object holding the data source's connection details.
handlerInfo.schema
string
The data source’s schema name in the source system.
handlerInfo.table
string
The data source’s table name in the source system.
handlerInfo.hostname
string
The data source’s connection schema in the source storage system.
handlerInfo.port
integer
The data source’s connection port in the source storage system.
handlerInfo.query
string
The data source’s connection schema in the source storage system, if applicable.
dataSource
dictionary
Object holding general data source information from Immuta. This can be viewed with debugging, but is not usually required for catalog purposes.
This object must be parsed by the in Custom REST Catalog order to determine the specific data source metadata being requested.
For the most part, Immuta will provide the id of the data source as part of the catalogMetadata. This should be used as the primary metadata lookup value.
{
"catalogMetadata": {
"id": <unique integer or string value>
}
}When a data source is being created, such an id will not yet be known to Immuta. Immuta will instead send handlerInfo information as part of the request.
{
"handlerInfo": {
"schema": "schema_name",
"table": "table_name"
}
}When an id is not specified, the schema and table name elements should be parsed in an attempt to identify the desired catalog entry and provide an appropriate id. If such a lookup is successful and an id is returned to Immuta in the catalogMetadata section, Immuta will establish an automatic link between the new data source and the catalog entry, and future references will use that id.
Example request:
curl -X POST 'http://<your_custom_rest_catalog>/dataSource' \
--header 'Authorization: Basic <base64 of username:password>' \
--header 'Content-Type: application/json' \
--data '{"catalogMetadata": { "id": "this_is_1_unique_id"}}'Response
The schema for the /dataSource response uses the same tag object structure from the /tags response, along with the following set of metadata keys for both data sources and columns.
catalogMetadata
dictionary
Object holding the data source's catalog metadata.
catalogMetadata.id
string or integer
The unique identifier of the data source in the catalog.
catalogMetadata.name
string
The name of the data source in the catalog.
description
string
A description of the data source.
tags
<tags object>
Object containing the data source-level tags.
dictionary
dictionary
Object containing the column names of the data source as its keys.
dictionary.<column>
dictionary
Object containing a single column's metadata.
dictionary.<column>.catalogMetadata.id
string or integer
The unique identifier of the column in the catalog.
dictionary.<column>.description
string
A description of the column.
dictionary.<column>.tags
<tags object>
Object containing the column-level tags as keys.
The returned JSON object should have a format very similar to
"catalogMetadata": {
"id": <unique integer or string>
},
"description": <string>,
"tags": {
"Parent": {
"id": <tag_id1>
},
},
"dictionary": {
"some_column_name": {
"catalogMetadata": {
"id": <col_id1>
},
"description": "This column has example data in it",
"tags": {
"Parent.Child1": {
"id": <tag_id2>
},
"Parent.Child1.Grandchild1": {
"id": <tag_id3>
}
}
}
}
}Example response:
{
"catalogMetadata": {
"name": "Example Data Source",
"id": "this_is_1_unique_id"
},
"description": "This description gets applied to the whole data source",
"tags": {
"Root": {
"id": "id_is_set_by_catalog_and_can_be_int_or_string"
}
},
"dictionary": {
"ColName1": {
"catalogMetadata": {
"id": 502342
},
"description": "This description gets applied to just this column",
"tags": {
"REST_Catalog_Root.Child1": {
"id": "d3e859da-40e9-43d2-a302-294458e79a64"
},
"REST_Catalog_Root.Child2": {
"id": 49294
},
"REST_Catalog_Root.Child2.Grandchild1": {
"id": "grand-kid-2"
}
}
}
}
}GET /dataSource/page/{id}
/dataSource/page/{id}Overview
This endpoint returns a human-readable information page from the REST catalog for the data source associated with {id}. Immuta provides this as a mechanism for allowing the REST catalog to provide additional information about the data source that may not be directly ingested by or visible within Immuta. This link is accessed in the Immuta UI when a user clicks the catalog logo associated with the data source.
Request
Immuta will send a GET request to the /dataSource/page/{id} endpoint, where {id} will be:
id
URL Parameter, integer or string
The unique identifier of the data source in the remote catalog system.
Example request:
curl http://<your_custom_rest_catalog>/dataSource/page/123Response
The Custom REST Catalog can either provide such a page directly, or can redirect the user to any resource where the appropriate page would be provided - for example a backing full service catalog such as Collibra, if this Custom REST catalog is simply being used to support a custom data model.
Example response:
<html>
<head>
<title>data source 123</title>
</head>
<body>
data source 123 is a data source that was created just for documentation.
</body>
</html>GET /column/{id}
/column/{id}Overview
This endpoint returns the catalog's human-readable information page for the column associated with {id}. Immuta provides this as a mechanism for allowing the REST catalog to provide additional information about the specific column that may not be directly ingested by or visible within Immuta.
Request
Immuta will send a GET request to the /column/{id} endpoint, where {id} will be:
id
URL Parameter, integer or string
The unique identifier of the column in the remote catalog system.
Example request:
curl http://<your_custom_rest_catalog>/column/10Response
The Custom REST Catalog can either provide such a page directly, or can redirect the user to any resource where the appropriate page would be provided - for example a backing full service catalog such as Collibra, if this Custom REST catalog is simply being used to support a custom data model.
Example response:
<html>
<head>
<title>data source 123 Column 10</title>
</head>
<body>
Column 10 is full of example data for documentation reasons.
</body>
</html>Last updated
Was this helpful?